August 15, 2025
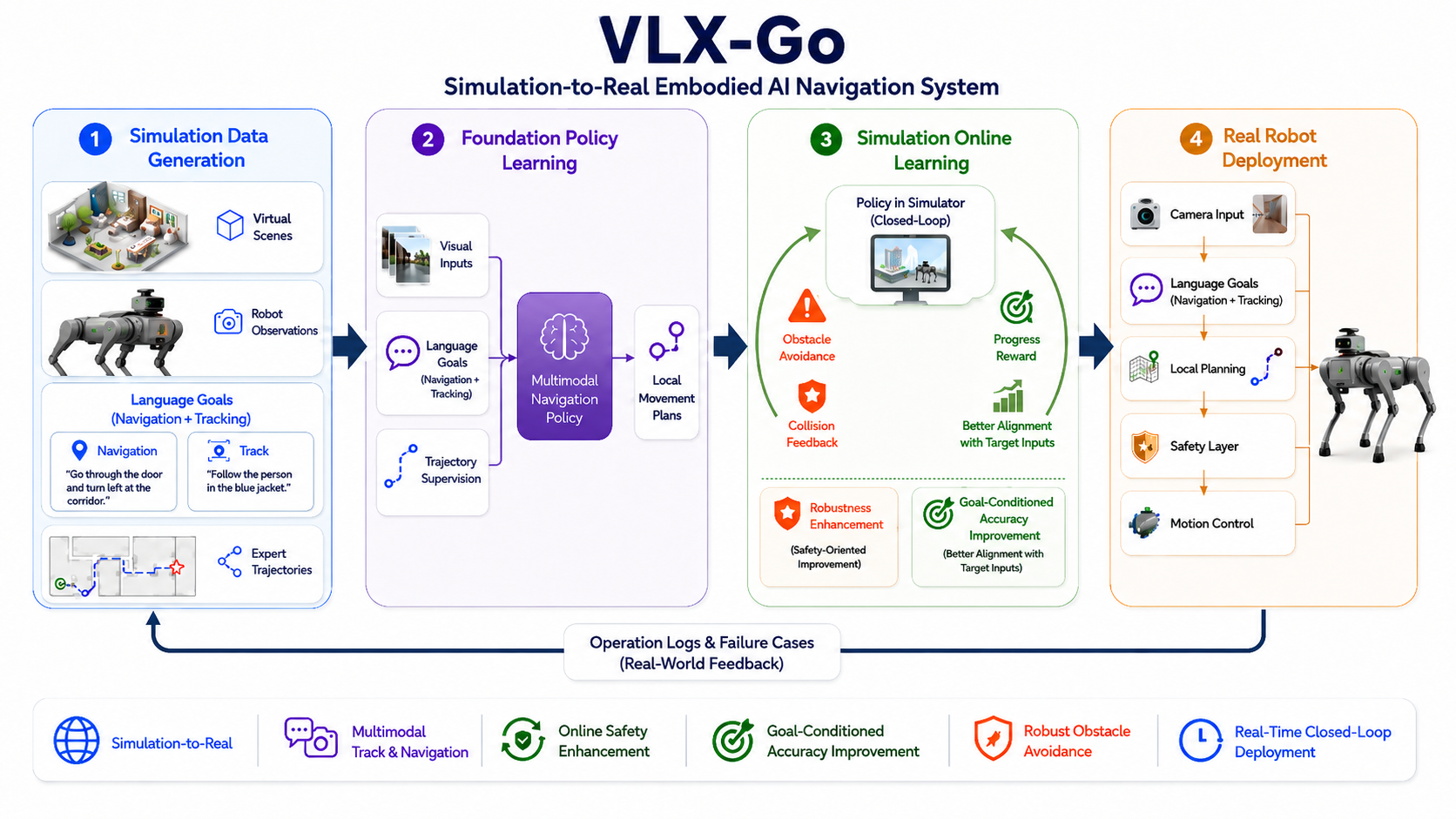
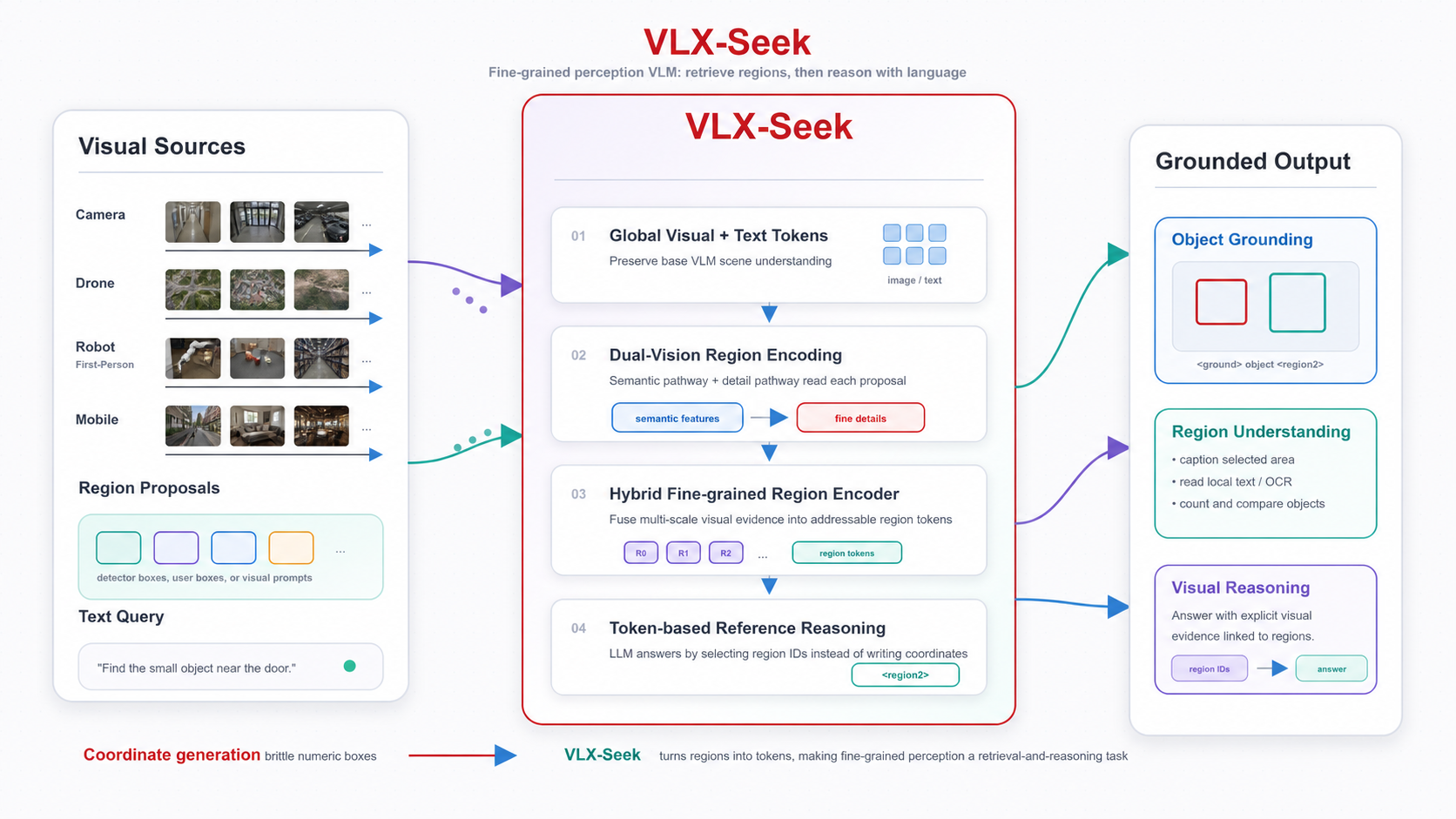
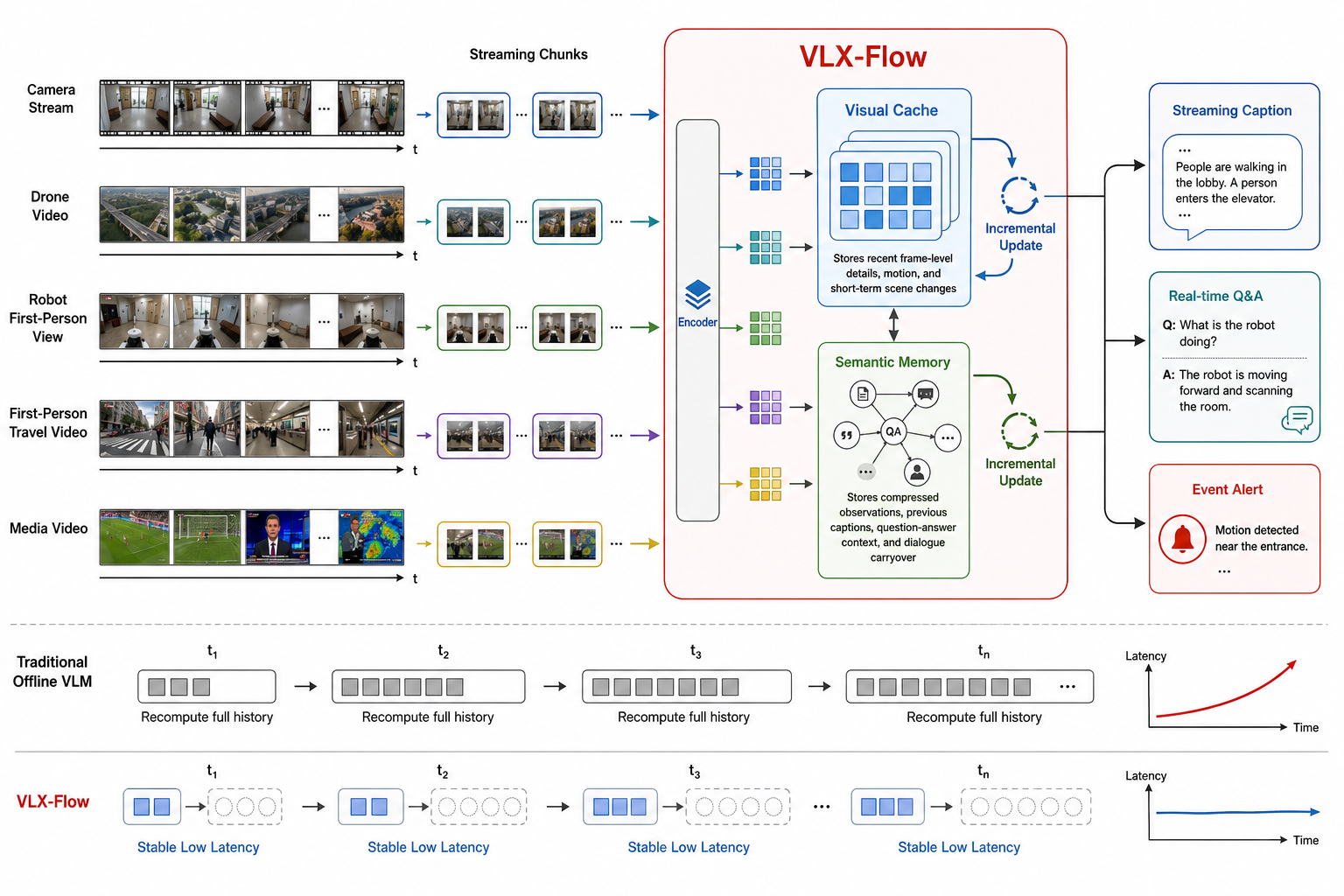
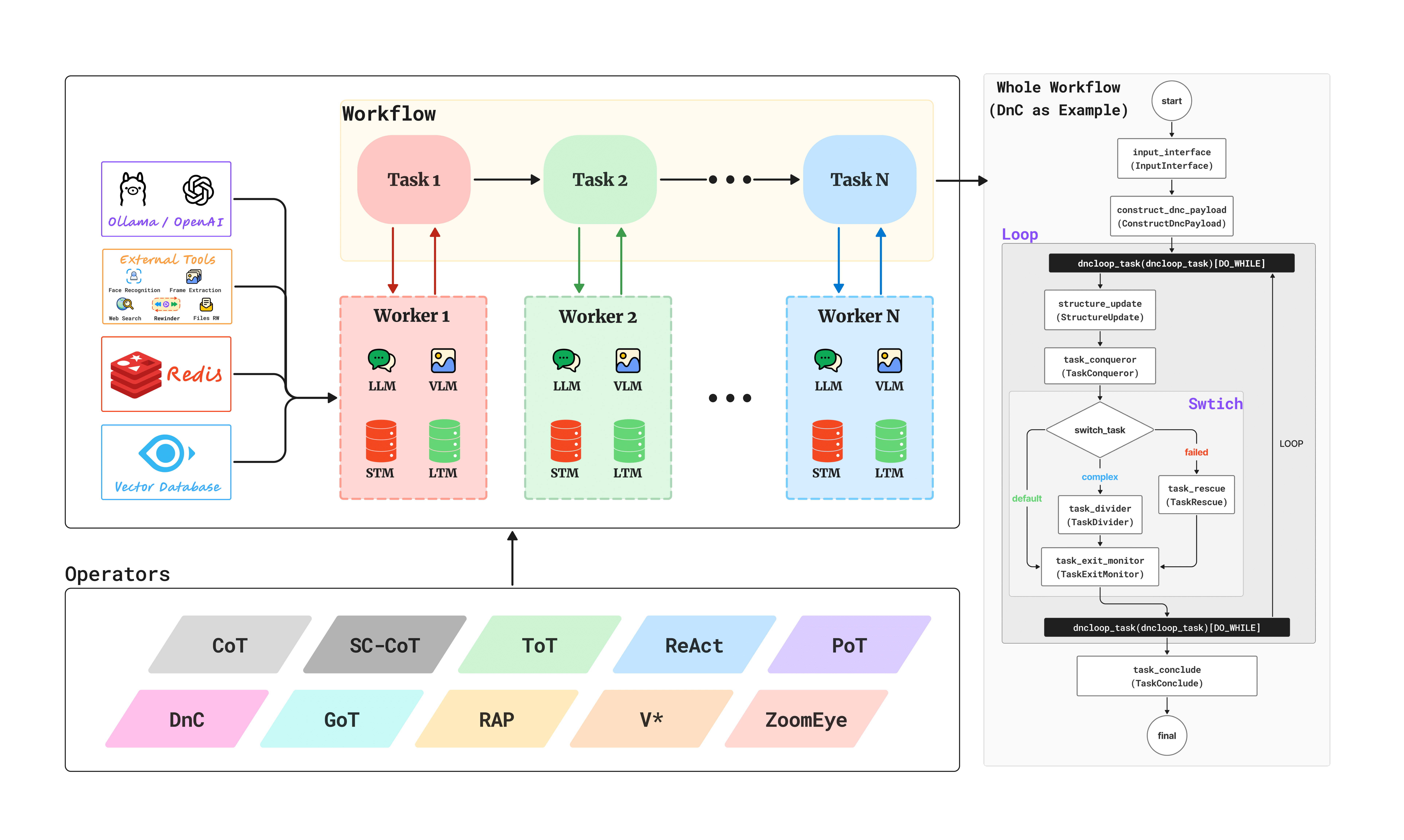
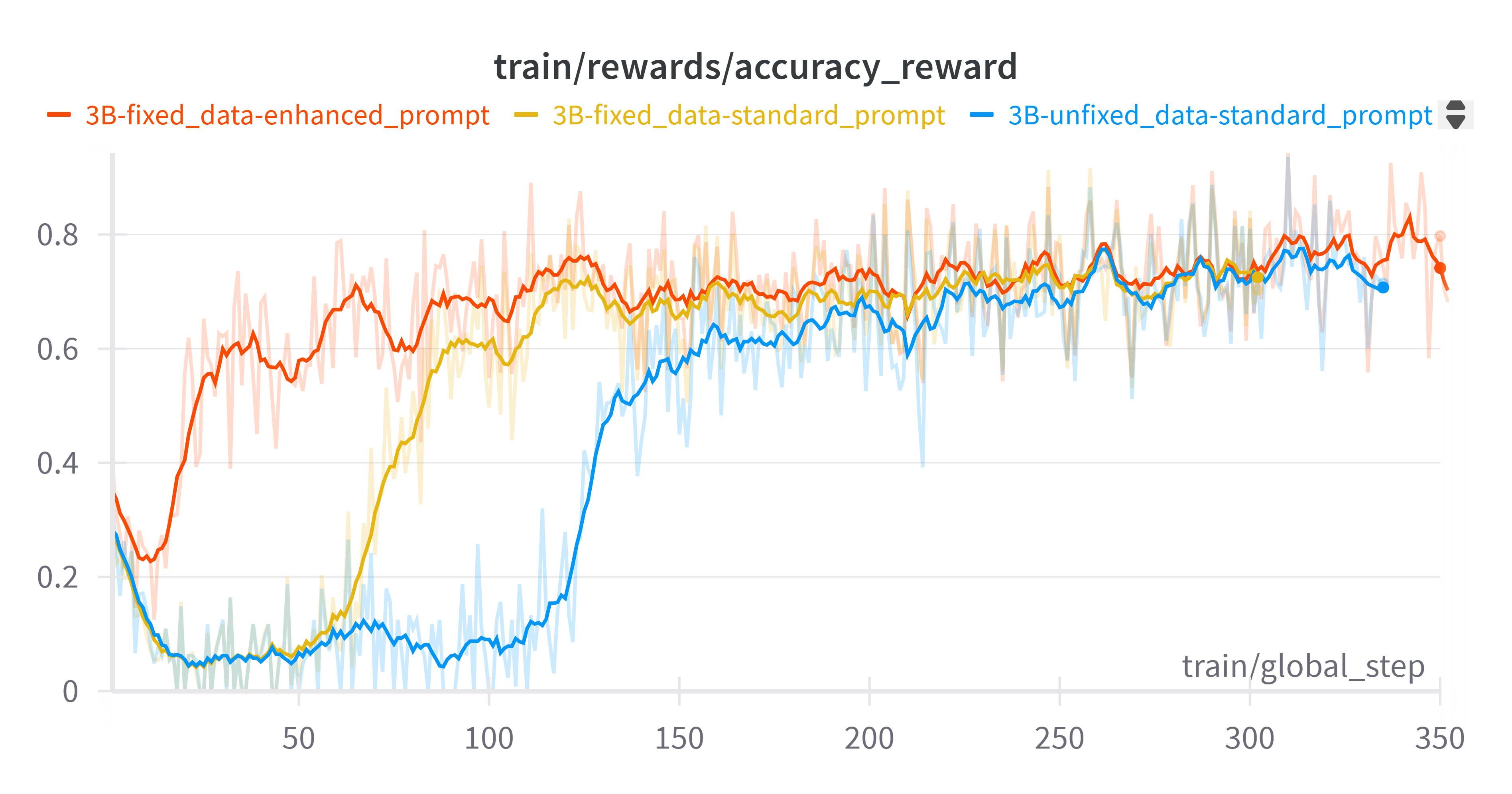
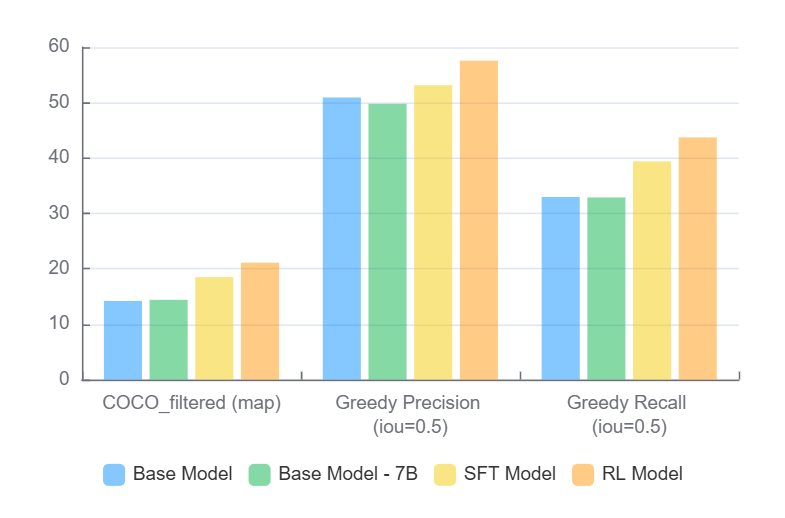
Existing Vision-Language Models (VLMs) excel at holistic scene understanding but fail at precise, object-centric tasks like detection, primarily due to their inability to generate accurate coordinates. We propose VLM-FO1, an approach that solves this by transforming object detection from a generation to a retrieval problem. We treat bounding boxes as visual prompts, extract their features into unique "object tokens", and feed them directly to the model. This method dramatically improves performance, with VLM-FO1-3B reaching 44.4 mAP on COCO, rivaling specialized detectors and demonstrating strong capabilities on other region-based perception tasks.
Read more →