TL;DR
This work demonstrates that reinforcement learning (RL) significantly enhances object detection performance compared to supervised fine-tuning (SFT) in vision-language models. Using the VLM-R1 framework (built on Qwen2.5-VL-3B) trained on the Description Detection Dataset (D³), RL achieved:
- 20.1% mAP on COCO (vs. 17.8% for SFT; 14.2% for 7B model)
- New SOTA 31.01 nms-AP on OVDEval (vs. 26.50 for SFT; 29.08 for 7B model), excelling in complex tasks like position (+9.2%) and relationship detection (+8.4%).
- Emergent "OD aha moment" reasoning: RL models spontaneously learned to filter irrelevant objects via an internal verification step before detection.
Key innovations include reward engineering to suppress redundant bounding boxes and length-controlled outputs, addressing critical limitations of traditional AP metrics. The results validate that RL learns generalizable detection principles rather than memorizing training data, advancing open-vocabulary object detection in real-world scenarios.
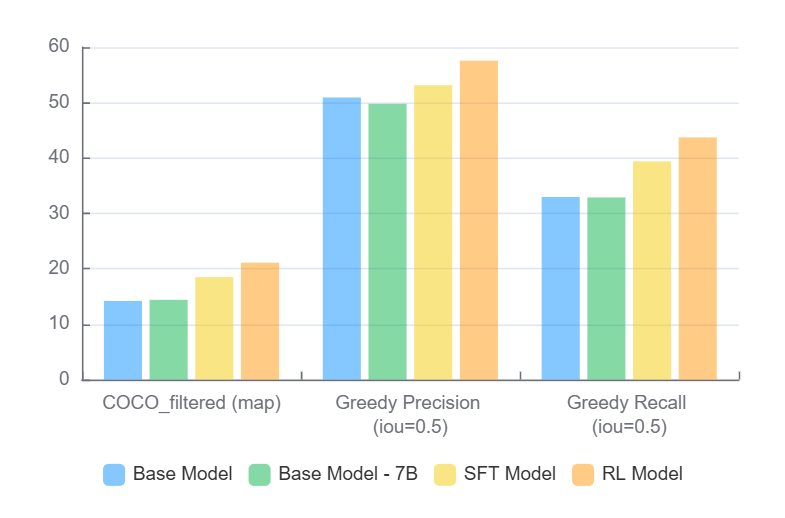
Results on filtered COCO val2017 set
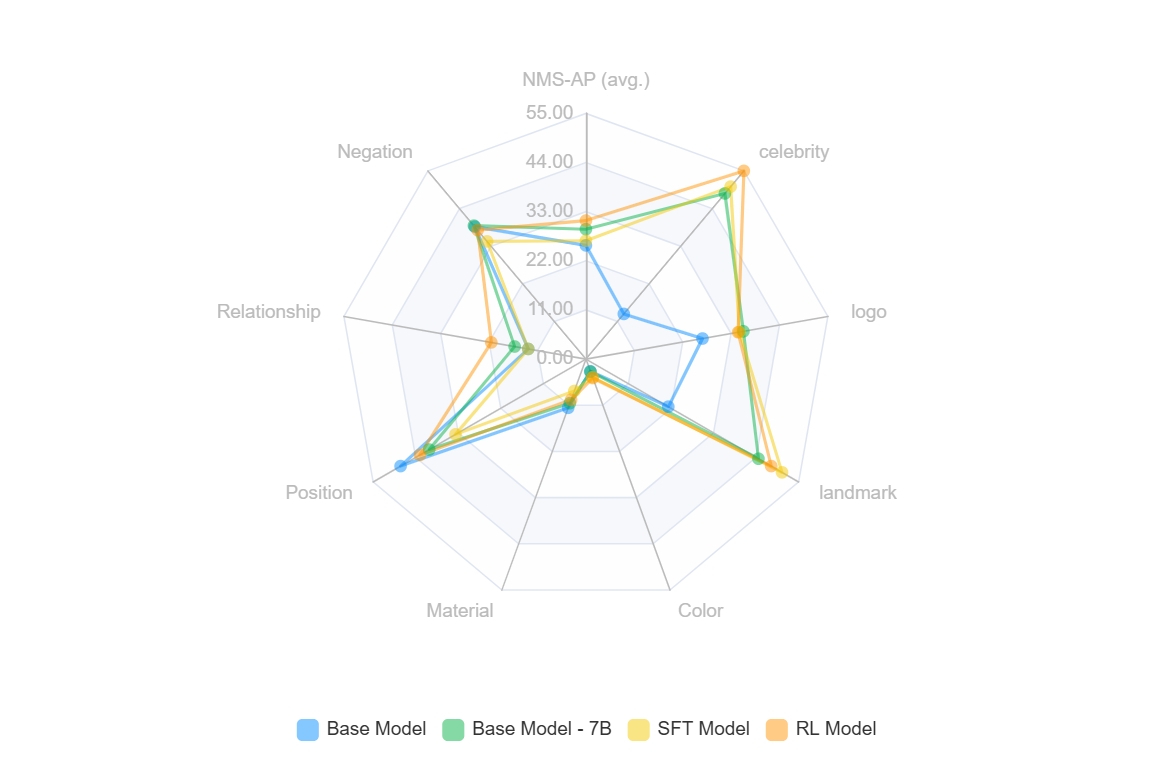
Results on OVDEval dataset
Introduction
Object detection remains a fundamental challenge in computer vision, particularly when dealing with flexible language descriptions and complex scenarios. In our recent work, we explored using reinforcement learning (RL) to enhance vision-language models' object detection capabilities using the VLM-R1 framework. Our findings align with recent research showing that RL approaches tend to learn more generalizable knowledge compared to supervised fine-tuning (SFT) methods (Chu et al., 2024).
One of the most surprising discoveries in our research was the emergence of an unexpected reasoning pattern (we called it "OD aha moment") in our RL-trained model. When presented with a detection task containing multiple potential objects (including hard negative labels), the model spontaneously developed a two-step approach: first explicitly filtering and identifying which objects are actually present in the image through a "thinking" step, then proceeding with precise bounding box detection. This emergent behavior was particularly interesting as it wasn't explicitly trained or prompted - the model independently learned to tackle complex scenarios by first reasoning about relevant objects before making detections. For example, when given a tennis court image with a mix of relevant objects and irrelevant items (like "white swan" or "incomplete apple"), the model first states its focus on tennis-related elements before outputting any bounding boxes, resulting in more accurate and efficient detection.
Object Detection "Aha Moment" Example

Given task: Please carefully check the image and detect the following objects:
- white swan in the water
- person playing tennis with a racket
- person wearing a hat on a tennis court
- tennis racket
- incomplete apple
- non-human mask
- volleyball on the beach
- person doing yoga
<think>
The task requires object detection. From analyzing the image, I can see this is a tennis-related scene.
Only tennis-related objects are present - specifically a player with a racket wearing a hat.
Other objects like swans, apples, masks, volleyballs and yoga poses are not in this image.
</think>
<answer>
```json
[
{"bbox_2d": [160, 17, 534, 507], "label": "person playing tennis with a racket"},
{"bbox_2d": [160, 17, 534, 507], "label": "person wearing a hat on a tennis court"},
{"bbox_2d": [146, 74, 228, 133], "label": "tennis racket"}
]
```
</answer>Methodology
We first try training on the most popular OD dataset - COCO, but did not see any improvement for both SFT and RL model over the base model. We hypothesize that the base model - Qwen2.5-VL-3B, is well-trained on COCO and cannot learn any new knowledge out of it. We end up conducting our experiments using the Description Detection Dataset (D³), which provides several unique advantages for training object detection models:
- Complete annotation coverage
- Unrestricted language descriptions
- Instance-level annotations
- Support for absence expressions
Our training process utilized the VLM-R1 framework, which builds upon the Qwen2.5-VL-3B model as the base architecture. Similar to the approach described in "SFT Memorizes, RL Generalizes," we explored both SFT and RL training paradigms to compare their effectiveness in learning generalizable detection principles rather than merely memorizing training data.
Evaluation Benchmark
OVDEval
To thoroughly evaluate our model's capabilities, we utilized OVDEval, a comprehensive benchmark designed specifically for testing open-vocabulary detection (OVD) models. OVDEval addresses several limitations in existing evaluation methods by:
- Systematic Generalization Testing: The benchmark consists of 9 sub-datasets covering 6 key linguistic aspects:
- Object detection
- Proper noun recognition (celebrities, logos, landmarks)
- Attribute detection
- Position understanding
- Relationship comprehension
- Negation handling
- Hard Negative Evaluation: OVDEval incorporates carefully selected hard negative labels, making it particularly effective at assessing real-world model performance. This is crucial for understanding how models handle challenging cases and ambiguous scenarios.
- Quality Assurance: All data is manually annotated by human experts to ensure high-quality ground truth, sourced from diverse datasets including HICO, VG, and Laion-400m.
- Improved Metrics: The benchmark introduces a new Non-Maximum Suppression Average Precision (NMS-AP) metric to address the "Inflated AP Problem" common in traditional evaluation methods. This provides a more accurate assessment of model performance by preventing artificially high scores from redundant predictions.
This comprehensive evaluation framework allows us to assess not just basic object detection capabilities, but also the model's ability to handle complex linguistic descriptions and real-world scenarios.
COCO filtered
The COCO dataset is created from the COCO dataset's instances_val2017.json file. Since VLMs generally struggle at recall in OD tasks (see ChatRex), we filter out categories with more than 10 annotation boxes, ensuring that only categories with fewer boxes are included.
Results and Analysis
COCO Dataset Performance
Our results on the filtered COCO val2017 set showed significant improvements across key metrics:
| Model | COCO_filtered (mAP) | Greedy Precision (IoU=0.5) | Greedy Recall (IoU=0.5) |
|---|---|---|---|
| Base | 14.2 | 50.93 | 32.97 |
| Base 7B | 14.4 | 49.79 | 32.88 |
| SFT Model | 18.5 | 53.15 | 39.4 |
| RL Model | 21.1 | 57.57 | 43.73 |
The RL-trained model demonstrated substantial improvements over the SFT model, with a 2.6 percentage point increase in mAP (21.1% vs 18.5%), 4.42 points higher in Greedy Precision (57.57% vs 53.15%), and 4.33 points better in Greedy Recall (43.73% vs 39.4%). These consistent improvements across all metrics demonstrate RL's superior generalization capability.
OVDEval Benchmark Results
On the comprehensive OVDEval benchmark, the RL model showed significant advantages over SFT in several key areas:
| Model | nms-ap (avg.) | Celebrity | Logo | Landmark | Color | Material | Position | Relationship | Negation |
|---|---|---|---|---|---|---|---|---|---|
| Base | 25.46 | 13.2 | 26.5 | 21.3 | 2.9 | 11.6 | 47.9 | 13.1 | 38.7 |
| Base 7B | 29.08 | 48.4 | 35.8 | 44.6 | 3 | 10.5 | 40.5 | 16.2 | 39 |
| SFT | 26.50 | 50.4 | 34.9 | 50.7 | 4.3 | 7.6 | 33.7 | 13.1 | 34.4 |
| RL | 31.01 | 55.0 | 34.6 | 47.9 | 4.5 | 9.7 | 42.9 | 21.5 | 37.7 |
| RL - SFT | +4.51 | +4.6 | -0.3 | -2.8 | +0.2 | +2.1 | +9.2 | +8.4 | +3.3 |
"SFT Memorizes, RL Generalizes"
Our findings strongly support the conclusions drawn by Chu et al. regarding the different learning behaviors of SFT and RL approaches:
- Generalization Capability: The RL model demonstrated superior generalization by outperforming SFT in 7 out of 9 detection categories. Most notably, it showed significant improvements in complex tasks requiring deeper understanding:
- Position detection (+9.2 points)
- Relationship detection (+8.4 points)
- Negation handling (+3.3 points)
- Visual Capabilities: While SFT showed strong performance in specific categories like Celebrity, Logo and Landmark detection, RL demonstrated more balanced improvements across different visual tasks, suggesting better overall generalization of visual understanding.
- Role of SFT vs RL: The results clearly demonstrate that while SFT can be effective for certain specific tasks, RL provides more comprehensive improvements. The 4.51 point improvement in average nms-ap (31.01 vs 26.50) indicates RL's superior ability to learn generalizable features rather than just memorizing training patterns.
Technical Insights
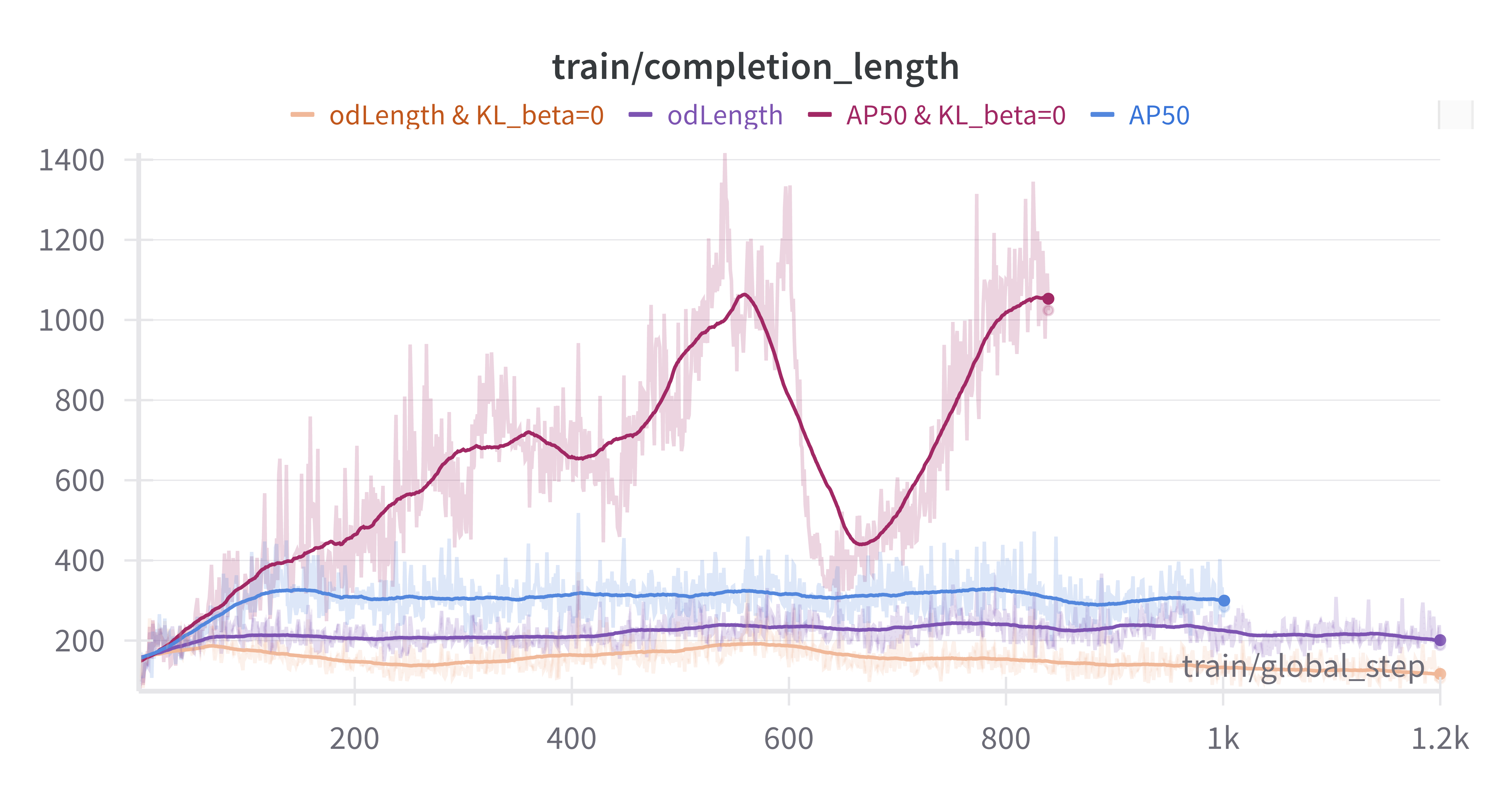
Through our experimental process, we made several key discoveries:
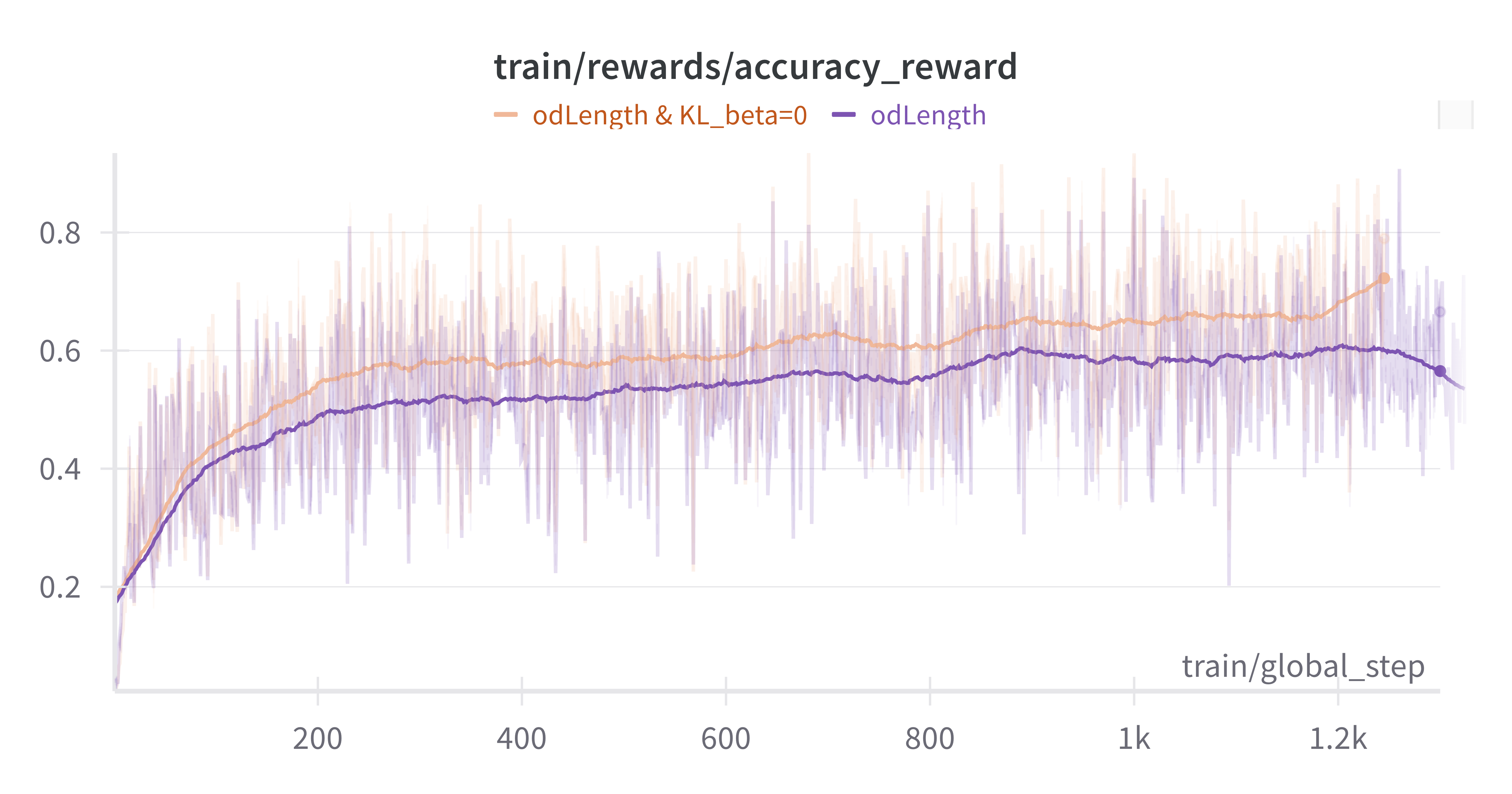
- KL Divergence Impact: Setting KL beta to 0 led to longer completion lengths but introduced early bounding box redundancy issues. This required additional reward engineering to control.
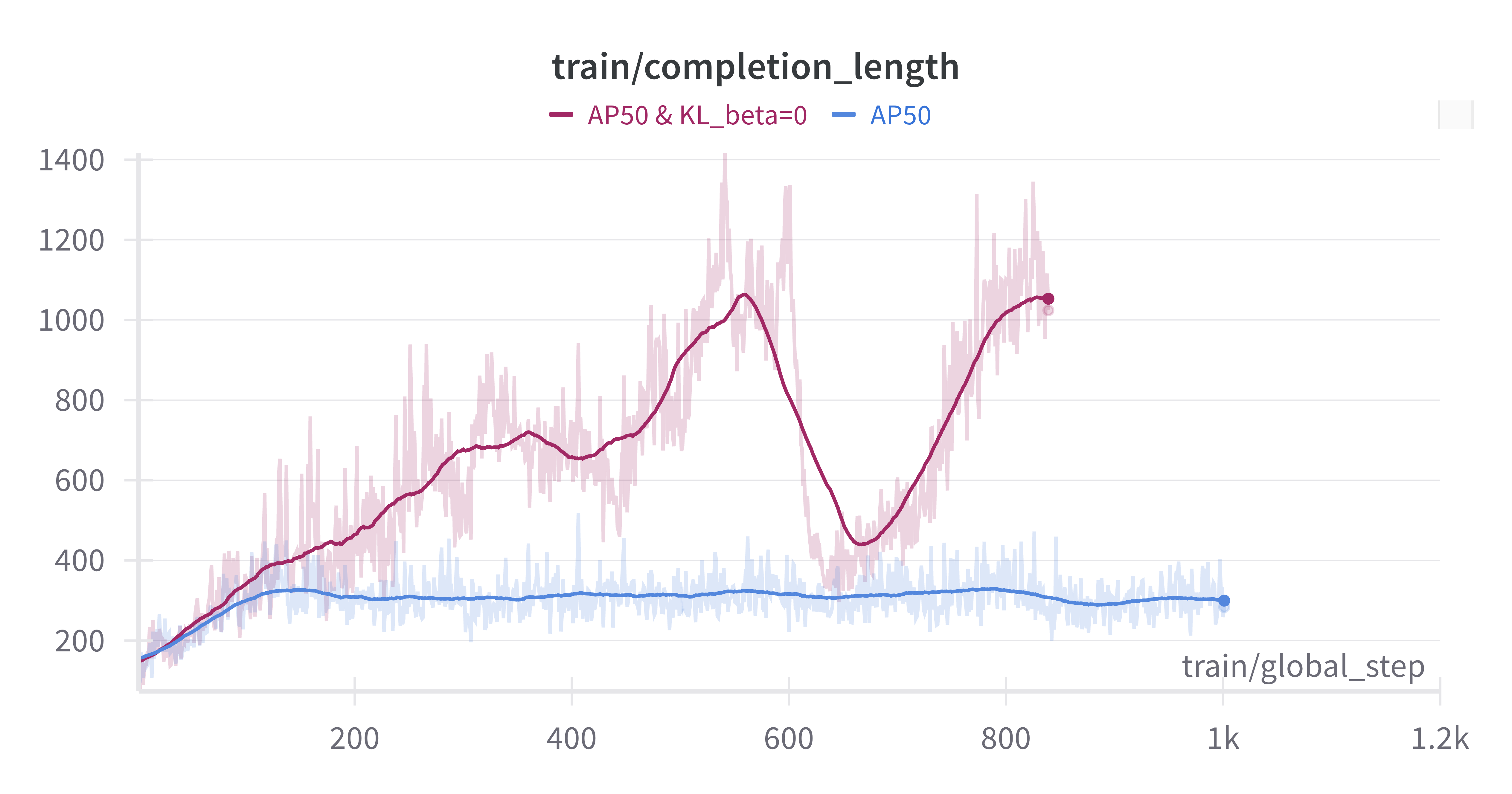
- AP or AP50 For Bounding Box: For VLM models, accurately predicting bounding box coordinates can be challenging. Initially, AP50 was used as a more lenient reward function to train the model. During evaluation, a confidence score of 1.0 was assigned to all predicted boxes, and the COCO mAP was calculated to determine the reward. Training results indicated that the model quickly achieved high scores on AP50, but its performance on mAP during evaluation was suboptimal. Comparisons showed that using the stricter AP metric for training yielded better results.
- Bbox Length Control Rewards: The mAP metric provides minimal penalties for excessive false-positive boxes, allowing models to exploit this by generating redundant boxes to artificially boost AP scores. This behavior is particularly evident when KL divergence is zero, as the model tends to produce more redundant boxes by increasing output tokens. To counteract this, a reward mechanism was implemented to suppress such behavior. The introduction of an "odLength" reward, which combines AP with bounding box length control, proved to be highly effective.
- COCO_filtered mAP improved from 11.4 to 18.8
- OVDEval average mAP increased from 12.0 to 30.2
- Output Characteristics: Models trained with KL=0 and length control produced more concise outputs while maintaining detection accuracy, suggesting better efficiency.
Comparison with State-of-the-Art OD: OmDet
OmDet represents the current state-of-the-art in specialized open-vocabulary detection, introducing innovations like the Efficient Fusion Head (EFH) and language caching to achieve real-time performance while maintaining high accuracy. However, our VLM-R1 model demonstrates that large vision-language models can outperform specialized architectures in several key aspects.
Comparing the overall performance on OVDEval:
- OmDet: 25.86 nms-ap
- VLM-R1 (RL): 31.01 nms-ap
- Improvement: +5.15 points (19.9% relative improvement)
This significant performance gap reveals interesting insights about the strengths and limitations of different approaches:
- World Knowledge and Entity Recognition:
- In celebrity detection, VLM-R1 achieves 55.0 nms-ap compared to OmDet's 1.8
- This dramatic difference (>50 points) demonstrates the value of VLMs' pre-trained world knowledge
- Similar patterns appear in logo and landmark detection, where semantic understanding is crucial
- Fine-grained Detection vs. High-level Understanding: The attribute category in OVDEval contains a lot of small objects.
- OmDet shows stronger performance in attribute detection (color: 41.98 vs 4.5)
- This suggests specialized architectures excel at fine-grained, local feature detection
- The gap is particularly noticeable for small objects where precise localization is critical
- Complex Reasoning Tasks:
- VLM-R1 significantly outperforms in relationship detection (21.5 vs 11.4)
- Better handling of negation (37.7 vs 35.1)
- Demonstrates VLMs' superior capability in tasks requiring contextual understanding
These comparisons suggest a promising future direction: combining the complementary strengths of both approaches. Specialized OD architectures excel at fine-grained detection and high-recall scenarios, while VLMs bring rich world knowledge and superior reasoning capabilities. Future research could focus on creating hybrid architectures that leverage both the precise localization abilities of dedicated OD models and the semantic understanding of VLMs.
Conclusion
Our exploration demonstrates that reinforcement learning is particularly effective at improving object detection performance while maintaining generalization capabilities. The combination of the D³ dataset with our enhanced VLM-R1 framework provides a robust foundation for future developments in this field.
The results suggest that careful reward engineering, particularly around output length control, plays a crucial role in achieving optimal performance. This aligns with the broader understanding that RL approaches can learn more generalizable principles rather than simply memorizing training data.
Source: VLM-R1 GitHub Repository