From Scene-level Understanding to Object-level Precision: The Next Evolution for VLMs
Large Vision-Language Models (VLMs) can now understand and describe complex scenes like a human. However, they often struggle when we ask them to handle more precise, object-centric tasks, especially object detection.
On standard benchmarks like COCO, specialized detection models can easily achieve an mAP of 50-60. In stark contrast, even state-of-the-art VLMs perform poorly, particularly in their ability to find all relevant objects (recall). For instance, a powerful open-source model like Qwen2.5-VL-72B only achieves a recall lower than 40%. This gap highlights a fundamental limitation: generating precise coordinates is an "unnatural" job for models that are fundamentally designed for language, reflecting their broader struggles with producing precise numerical outputs (Why Large Language Models Fail at Precision Regression, Selvam, 2025).
Today, we are excited to announce VLM-FO1 (VLM-Finegrained Object V1), a new model designed to solve this core challenge.
The core idea behind VLM-FO1 is simple: we no longer force VLMs to "draw" boxes. Instead, we teach them to directly perceive the content within them. We treat any bounding box as a visual prompt, extract the object-level features from the region it defines, convert these features into distinct "object tokens", and feed them directly into the model. This approach elegantly transforms the complex task of Object Detection from an inefficient "generation" problem into a simple and accurate "retrieval" task. With this approach, VLM-FO1 improves by more than 20 points on COCO; our VLM-FO1-3B model achieves 44.4 mAP, which is on par with specialized detection models and far surpasses other VLMs. As we will show, this also leads to strong performance on a wide variety of other region-related perception tasks.

New Capabilities Unlocked by VLM-FO1
The power of VLM-FO1 lies in its flexibility. Because the object features can be extracted from bounding boxes supplied by any detection model—or even from any custom-defined rectangle acting as a visual prompt—the model's capabilities extend far beyond simple detection improvements. This versatility unlocks a suite of brand-new functionalities.
Capability 1: SOTA-level Object Detection and REC
- OD:

- REC:

- Grounding:

Capability 2: Precise Region Understanding
VLM-FO1 can use bounding boxes as a "visual prompt" to perform a deep dive into specific regions of an image.
- Region Caption:

- Region VQA:

- Region OCR:

Capability 3: Object Counting with OD
As shown in "LVLM-Count: Enhancing the Counting Ability of Large Vision-Language Models" (2025), VLMs often struggle with counting objects, particularly as quantities increase, due to limitations in their numerical reasoning. VLM-FO1 excels at this by adopting a Chain-of-Thought style process: it first detects all relevant objects and then counts them. This methodical approach helps it overcome these common failures, providing reliable results even in dense and cluttered scenes.

Capability 4: Object-Level Reasoning
VLM-FO1's architecture unlocks more complex, object-level reasoning processes. Instead of just answering a question, the model can first identify and analyze the most relevant object or region, and then formulate an answer based on that localized analysis. This enables smarter VQA, such as finding a specific item to read its label, and more precise detection by finding all potential candidates before filtering them to find the correct target. This ability to break down problems by first grounding them in specific visual evidence makes any complex reasoning task more tractable and accurate.

Performance that Speaks for Itself: Dominating the Benchmarks
To rigorously evaluate VLM-FO1, we tested it across a comprehensive suite of benchmarks spanning a wide range of object-level tasks. In every category, VLM-FO1 demonstrates state-of-the-art performance, proving its effectiveness and versatility.
Below is a summary of the results.
Object Detection (OD)
- Benchmarks: COCO, ODinW13, OVDEval
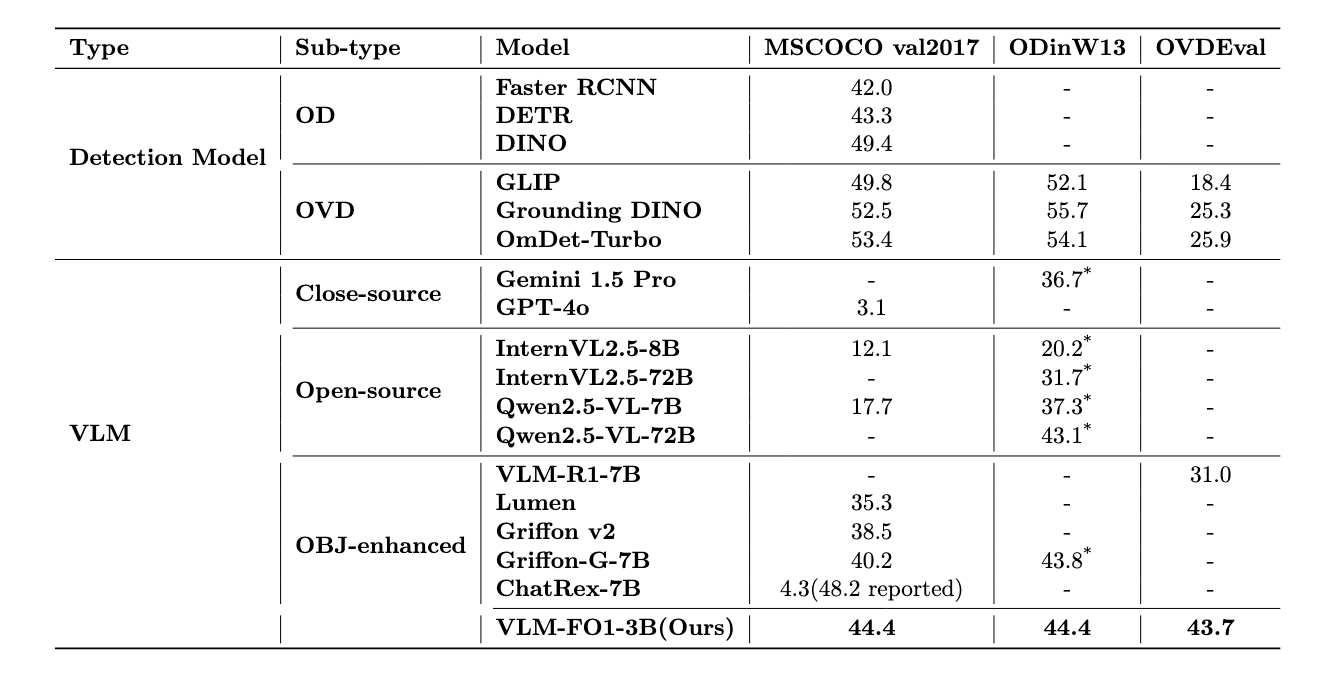
The results for Object Detection clearly show VLM-FO1's superiority. On standard benchmarks for common objects like COCO and real-world settings with rare categories in ODinW13, VLM-FO1 significantly outperforms other VLM-based models, demonstrating its powerful perception and higher recall. More impressively, on OVDEval, which evaluates performance on linguistic labels with hard negatives, VLM-FO1 surpasses not only other VLMs but also specialized detection models. This highlights a key advantage: VLM-FO1 leverages the world knowledge, entity recognition, and reasoning abilities inherited from its VLM foundation.
This performance starkly contrasts with other leading VLMs. For example, when asked to directly generate coordinates on COCO, GPT-4o achieves a mere 3.1 mAP, confirming that even the most advanced models struggle with direct bounding box regression. Similarly, while ChatRex-7B reports a high mAP of 48.2, this is achieved under a non-standard evaluation. Under the standard COCO protocol, its performance plummets to 4.3 mAP, likely due to an inability to distinguish negative labels. VLM-FO1 successfully overcomes both of these fundamental challenges.
More impressively, on ODinW13, our model achieves the highest score despite being tested under the rigorous, standard mAP protocol. It's important to note that many other VLMs (marked with *) are evaluated on ODinW13 using a simplified setting where only ground-truth categories are fed to the model one by one. This easier setting avoids the challenge of distinguishing hard negatives. Even against models tested in this simpler way, VLM-FO1, under standard evaluation, still comes out on top, underscoring its robust perception and recall capabilities.
Referring Expression Comprehension (REC)
- Benchmarks: Refcoco/+/g, HumanRef
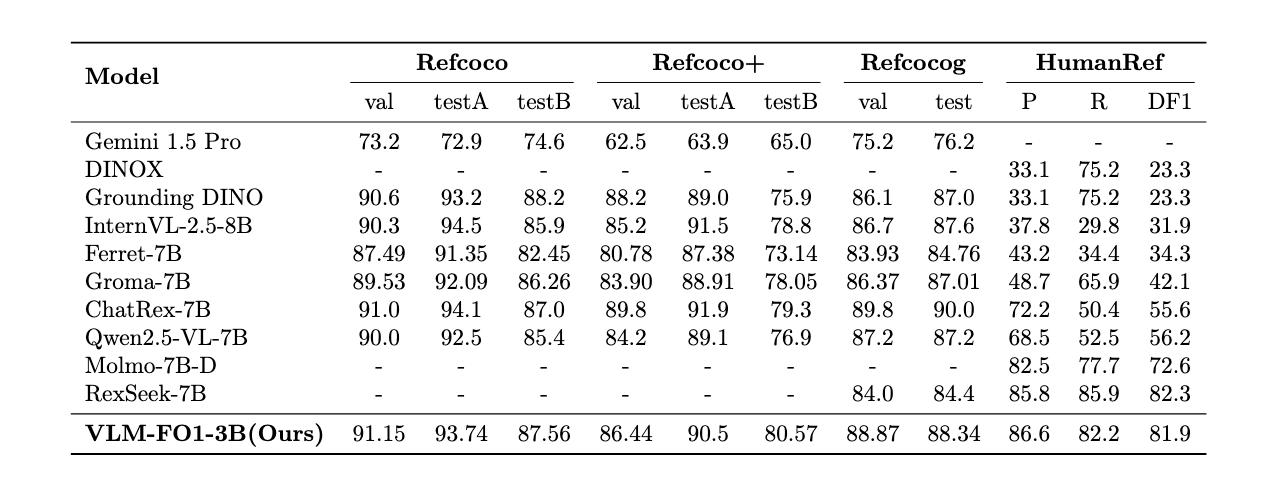
In the REC task, which tests a model's ability to locate an object based on a natural language description, VLM-FO1 again demonstrates its leading capabilities. On the common refcoco/+/g benchmarks, our model consistently achieves top-tier results. More importantly, on HumanRef, a more challenging benchmark focusing specifically on people with hard negatives and multiple instances, VLM-FO1 shows remarkable performance. This success on a difficult, human-centric task underscores the model's robust fine-grained understanding and its ability to disambiguate between similar-looking instances.
Region-Level Classification
- Benchmarks: LVIS-SS, PACO-SS
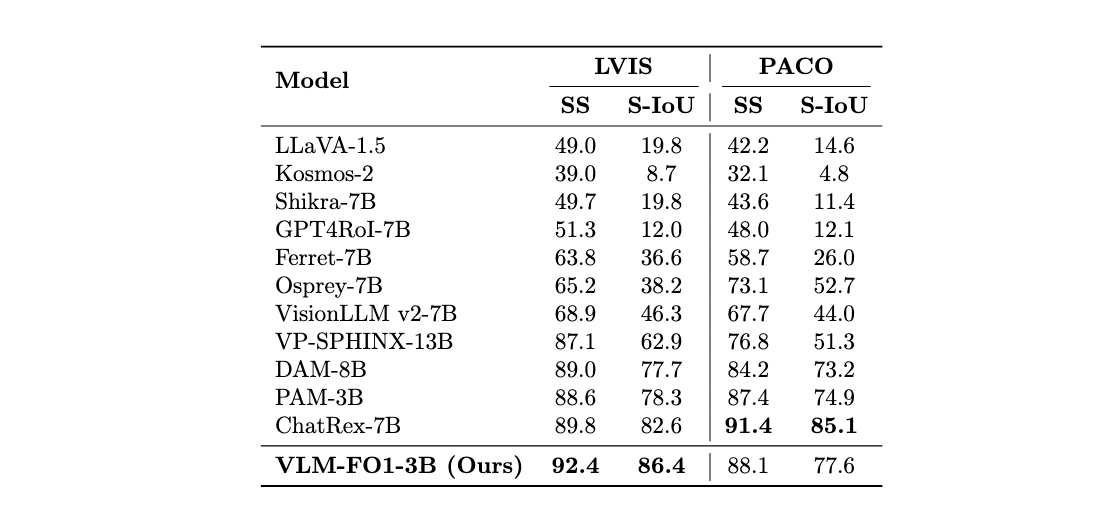
Region-level classification directly challenges a model's core region-to-text capability—its ability to accurately describe the content of a specific visual region with a precise textual label. This is a fundamental test of fine-grained understanding. We evaluated VLM-FO1 on the object-level LVIS dataset and the more difficult part-level PACO dataset, using Semantic Similarity (SS) and Semantic IoU (S-IoU) as metrics. The results are unequivocal: VLM-FO1 sets a new state-of-the-art on LVIS, outperforming all other models. This demonstrates its exceptional ability to generate accurate labels for objects at a fine-grained level. Remarkably, our highly efficient 3B parameter model surpasses many significantly larger models (7B, 8B, and even 13B), highlighting the power and effectiveness of our approach. Furthermore, its strong performance on the PACO dataset proves its capability extends to the even more challenging and nuanced task of identifying and classifying parts of an object.
Region-OCR
- Benchmark: COCOText
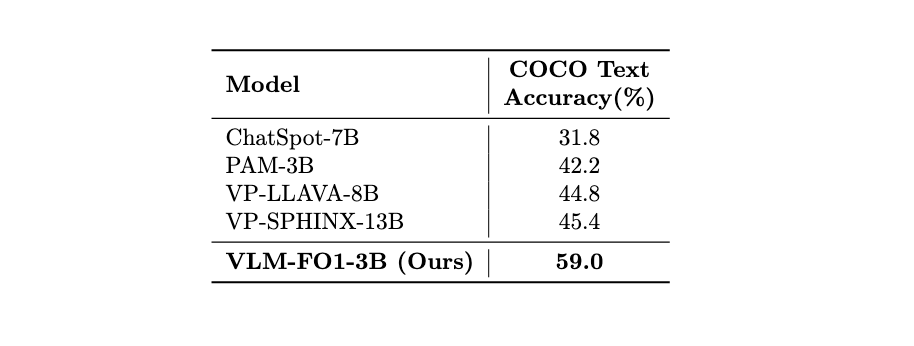
The COCOText benchmark is designed to assess regional text recognition. Given a ground-truth bounding box, the model's task is to accurately extract the textual content from within that specific region. As the results show, VLM-FO1 achieves a staggering 59.0% accuracy, establishing a new state-of-the-art by a massive margin. It outperforms the next best model by over 13 absolute points, once again proving that our model's architecture is exceptionally effective at focusing on and interpreting the content of specific visual prompts.
Referring Reasoning
- Benchmarks: Ferret Bench
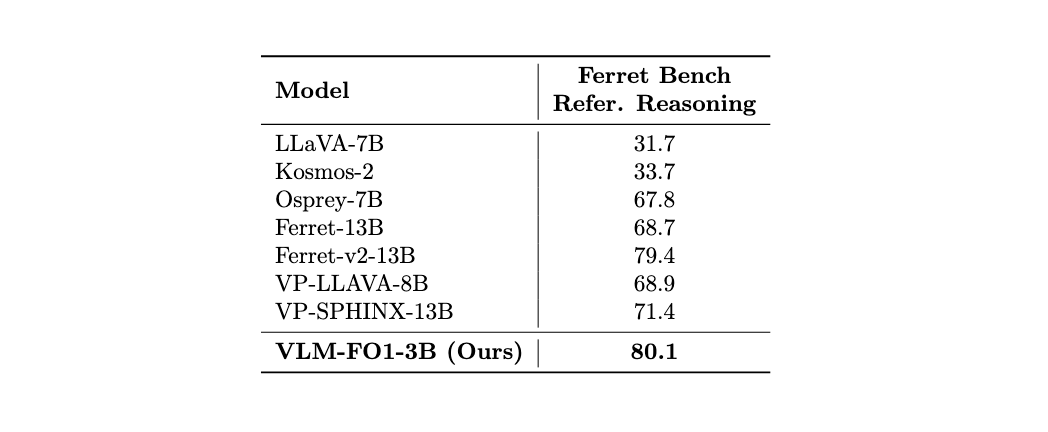
Beyond simple perception, true intelligence requires reasoning. We tested VLM-FO1 on the referring reasoning subset of Ferret Bench, where the model must reason about the relationships and properties of one or more specified regions. VLM-FO1 achieves a new state-of-the-art score of 80.1, outperforming even much larger 13B models. This result is crucial because it shows that superior perception is a direct prerequisite for superior reasoning. By first accurately understanding the content within each visual prompt, VLM-FO1 can then apply its powerful reasoning capabilities more effectively, leading to more accurate and reliable conclusions.
Object Counting
- Benchmarks: CountBench, Pixmo-Count
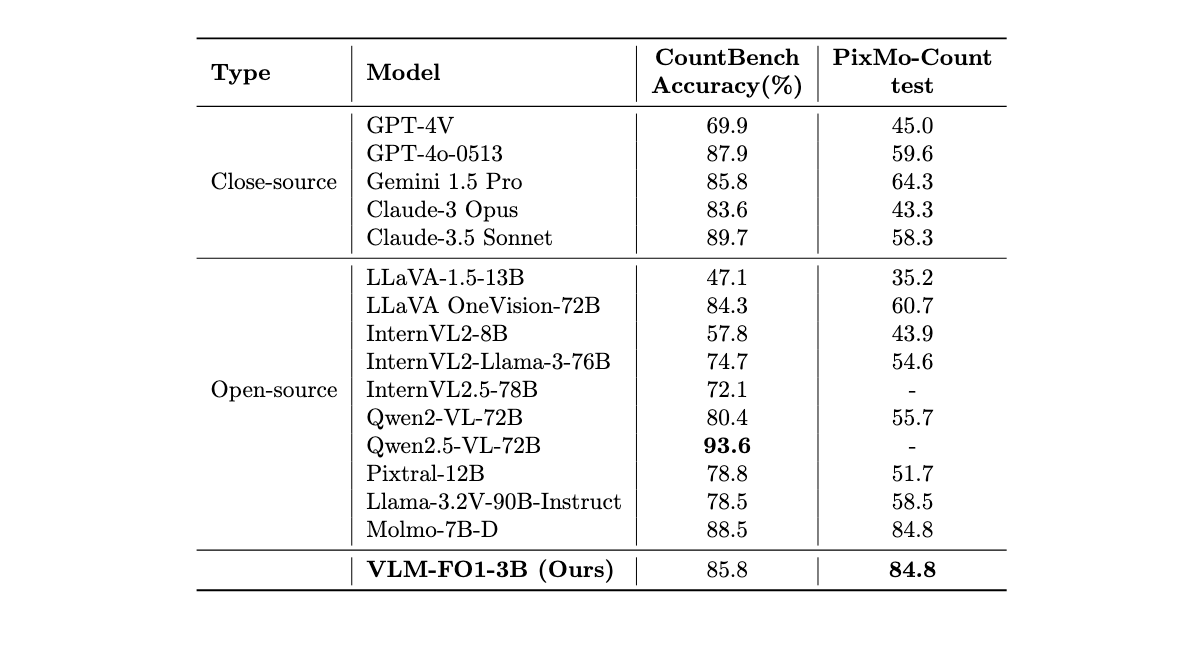
Object counting is a deceptively difficult task where many large VLMs struggle. Our evaluation on CountBench and the more challenging PixMo-Count shows that VLM-FO1 excels. Our model adopts a Chain-of-Thought style process—it first detects all instances of the target object and then counts them—leading to significantly higher accuracy. This methodical approach allows our compact VLM-FO1-3B to achieve results that are not only competitive with but often superior to much larger closed-source models like GPT-4V and open-source models up to 72B parameters. This highlights the remarkable efficiency and accuracy of our fine-grained perception method.
Enhanced, Without Forgetting
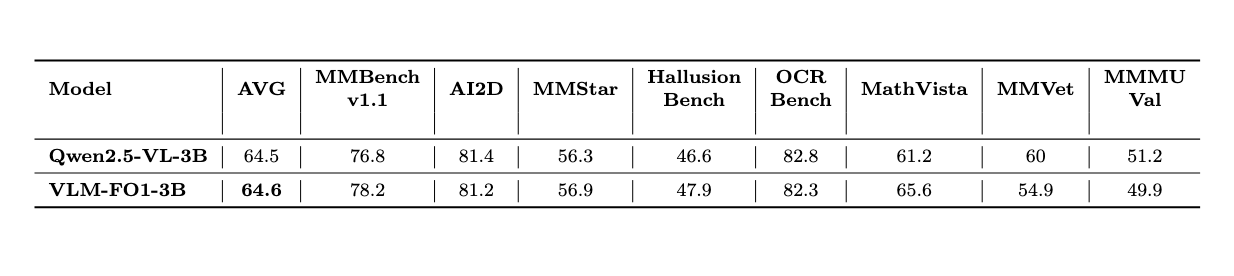
How did we achieve all this? The key to VLM-FO1 is its unique training strategy, which seamlessly injects object features identified by an external detector into a pre-trained VLM.
More importantly, our method is a "plug-and-play" enhancement module. It grants VLM with enhanced object-level perception capability without compromising the model's original abilities.
To validate this, we applied the VLM-FO1 training strategy to the Qwen-VL 2.5 model. The results showed that its scores on core VLM capabilities in OpenCompass remained virtually undiminished.
This means VLM-FO1 can be easily applied to any pre-trained VLM, allowing it to retain its powerful, general-purpose abilities while gaining superior, fine-grained object perception.
Conclusion and Future
By transforming object detection into a retrieval task, VLM-FO1 opens the door for vision-language models to perceive the world in fine-grained detail. It not only achieves leading results on multiple benchmarks but also demonstrates a range of exciting new applications.
We believe this is just the beginning. The road ahead is exciting, and we are exploring several future directions:
- Open Access: We plan to open-source the model weights and release an interactive demo to allow the community to experience VLM-FO1's capabilities firsthand.
- Scaling Up: We are currently training a larger 7B parameter version of VLM-FO1 and will be releasing its impressive scores soon.
- Towards End-to-End Perception: We are exploring methods to make the model fully end-to-end, for example, by enabling the VLM to generate its own high-quality bounding box proposals, reducing its reliance on external detectors.
- Advanced Reasoning: We aim to integrate VLM-FO1 with our upcoming VLM-FO1-R1 model, leveraging reinforcement learning to unlock the potential for complex, object-level reasoning and decision-making.
- Build Cross-Dimension Reasoning Capability: Develop a unified feature alignment module to bridge 2D visual tokens, 3D object tokens, and language tokens. This allows the model to perform tasks like "describing the relative position of two objects in 3D space" or "generating 3D scene layouts based on text instructions", thereby endowing VLMs with stronger spatial understanding and interaction capabilities for real-world scenarios.