1. 引言
随着大型语言模型(LLMs)与视觉语言模型(VLMs)的能力飞速发展,AI 技术正从「应试式」的任务达标转向「实战化」的复杂问题解决。用LLMs和VLMs去解决更实际更复杂的问题,而不是简单地通过“考试”, 这既是技术演进的必然方向,也是产业落地的核心诉求。与此同时,大语言模型催生的智能体(Agent)浪潮,正持续拓展 AI 在物理世界的应用边界:从 GUI 界面的在线购物操作,到具身机器人的家务劳动执行,让智能体像人类一样实现环境感知、思考规划与决策交互,已成为学术界与产业界共同面临的挑战。
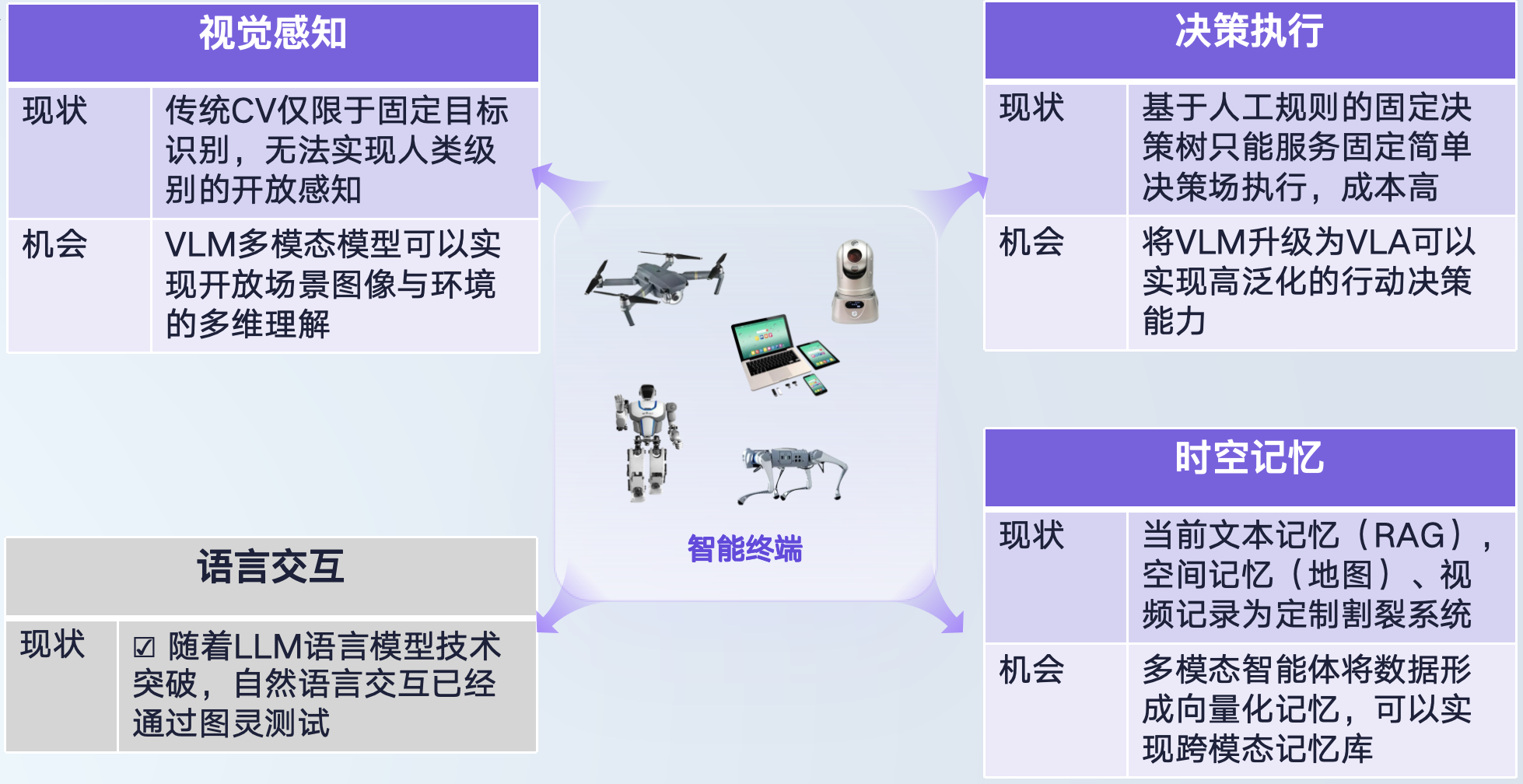
用户真正需要的是能在物理世界中交付结果、完成实际任务的「通用智能体」。基于这一目标,我们聚焦于探索一条可落地的技术路径:构建能在物理世界解决各类问题的AI 智能体,使其可部署于终端设备,成为智能终端的「核心大脑组件」。未来,无论是手机、摄像头、机器人还是无人机,都有望通过这一技术成为具身智能 AI Agent,并应用到工业管理、医疗诊断、个人助理、媒体创作等多元领域。要实现这样的具身智能 AI Agent,我们需要突破四大核心能力:视觉感知、决策执行、语言交互与时空记忆。其中,语义交互能力已通过当前 LLMs 得到初步解决,而其余三者则是待突破的关键 —— 这既是挑战,也是技术革新的机遇。今年 2 月,我们发布的强化学习驱动 VLM-R1 模型引发业界广泛关注:通过将 DeepSeek 在自然语言领域的推理能力延伸至视觉语言场景,验证了「强化学习提升 VLM 视觉感知与复杂环境推理能力」的技术路径。近期,我们进一步将这一路径拓展至决策执行领域,并结合原生多模态智能体框架,推出全球首个具身智能 AI Agent——OmAgent,一个基于强化学习的多模态智能体框架,并在实际应用中验证了该路径的可行性。
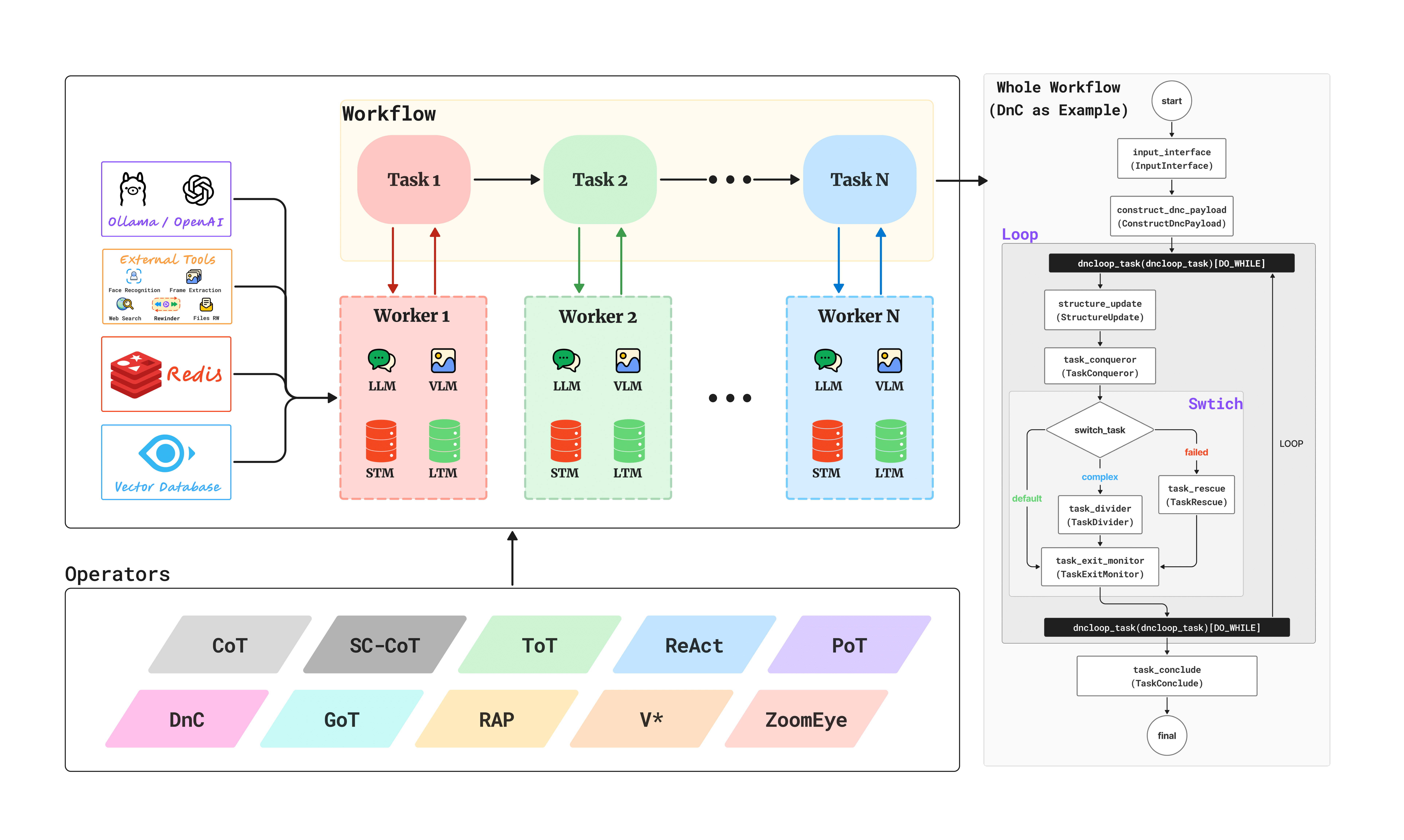
2. 方法
OmAgent是一个基于强化学习的多模态智能体框架。 该框架的核心理念是"简化复杂性",将复杂的工程实现(如时空记忆管理、工作流编排、任务队列、节点优化等)封装在后台,为开发者提供极其简洁易用的python接口。其具有以下特点:
原生多模态支持
- VLM模型集成:内置对主流视觉语言模型的支持,包括Qwen2.5-VL、LLaVA、InternVL等。
- 视频处理能力:原生支持视频输入和处理,实现视频理解和分析。
- 移动设备连接:支持与移动设备的无缝连接,实现跨平台智能体部署。
可重用组件抽象
- 模块化设计:通过基础组件构建复杂智能体,提高开发效率。
- 组件库生态:丰富的预构建组件,覆盖常见的AI任务场景。
- 自定义扩展:灵活的扩展机制,支持开发者自定义组件。
零复杂度开发体验
- 简洁API设计:避免其他智能体框架的繁重开销。
- 自动化工程:后台自动处理复杂的工程实现细节。
- 快速原型开发:从想法到原型,仅需几行代码。
OmAgent框架是解决智能终端的核心组件。通过对原生多模态的支持和零复杂度的开发,可以轻松应用于不同的终端设备。同时,内置的基础算法模块与工具集,可以快速解决智能终端所需要的环境感知,交互,决策执行相关的记忆存储的挑战。对于视觉感知和决策执行的能力要求,我们通过将强化学习模型集成到OmAgent进行突破,让终端能在动态复杂环境中保持对环境感知的鲁棒性和对环境决策执行的有效性。
2.1 视觉感知能力突破 - 基于强化学习的极致环境感知
我们在视觉感知领域的技术积累可追溯至 2021 年发布的 OmDet 模型系列。经过多轮迭代升级,该模型从早期基于属性关系的万物感知能力,逐步进化为支持自然语言驱动的高效识别模式;配合轻量级训练与部署方案,OmDet 能够对周边环境实现快速的开放域感知与理解。2023 年,我们推出了mChat,并通过持续更新不断强化其对视觉 - 语言混合环境的感知与交互能力。2025 年初,借由 DeepSeek 技术突破的契机,我们将强化学习成功引入视觉语言模型领域,研发并推出 VLM-R1 模型。该模型在目标检测等多项视觉感知任务中,性能显著优于传统监督学习方法,让我们在视觉领域也捕捉到了类似认知突破的 “aha moment”。值得一提的是,通过在多类任务中开展训练验证,我们发现基于强化学习的 OmR1 模型在跨任务场景下展现出优异的泛化能力,为复杂环境中的视觉感知与决策提供了更灵活的技术支撑。
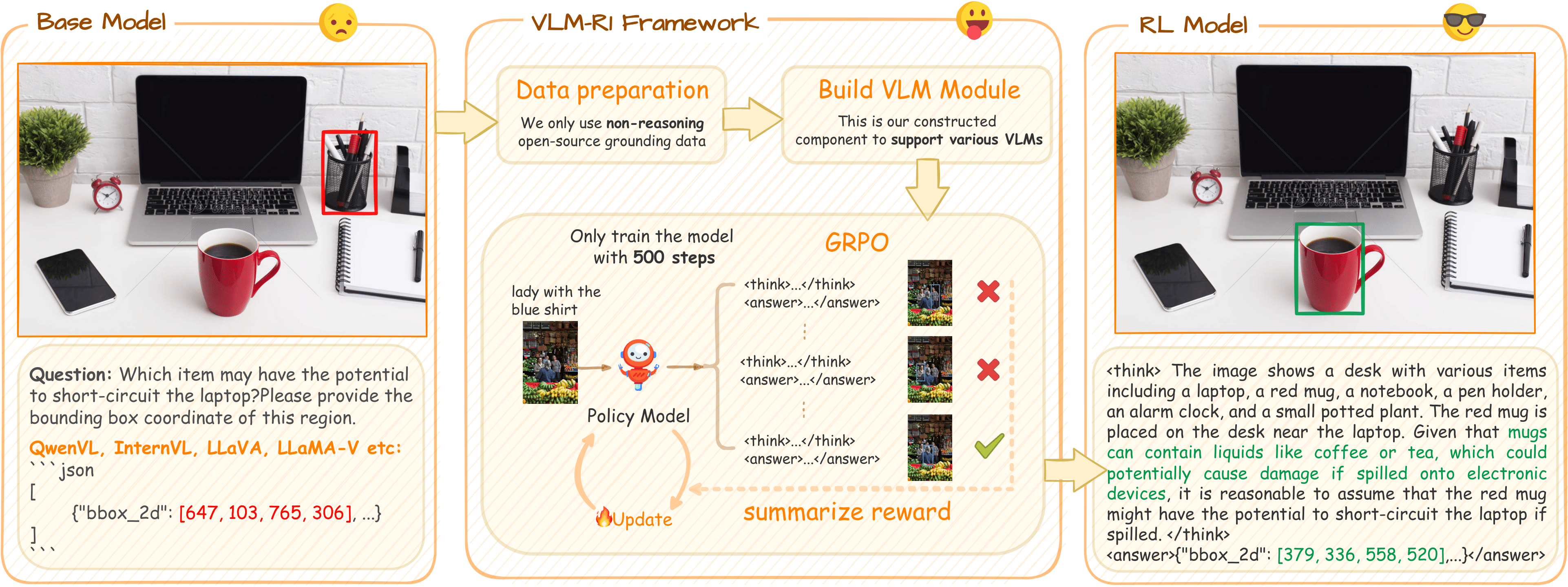
VLM-R1核心技术创新主要包括:
- GRPO算法集成:
- 完整支持:全面支持GRPO 算法用于VLM模型。
- 超参数控制:细粒度控制所有训练超参数。
- 稳定训练:通过规则化奖励设计实现稳定的RL训练过程。
- 模型支持:支持不同规模VLM模型训练,3B至72B都兼容。
- 参数高效训练:
- LoRA技术:支持基于LoRA的参数高效训练,适应有限资源环境。
- 多节点训练:支持跨多个GPU或服务器节点的分布式训练。
- 高效训练:优化内存使用和训练速度。
- 多模态数据处理:
- 混合模态训练:同时支持图像-文本和纯文本数据集训练。
- 动态批处理:批处理策略,提高训练效率。
- 多任务支持:
- REC任务:针对指称表达理解任务的专门奖励设计。
- OVD任务:开放词汇目标检测任务的奖励优化。
- 可扩展性:支持自定义奖励函数,适应不同任务需求。
在研究中,我们发现在视觉语言模型中,顿悟时刻 - "OD aha moment" 同样发生了,这是模型在强化学习训练过程中自发涌现的智能行为:
- 两步推理过程:模型自主学习了先过滤无关对象,再进行精确检测的策略。
- 内部验证机制:在输出检测结果前,模型会进行内部"思考"和验证。
2.2 具身智能决策执行 - 模拟人类与环境交互执行
通过对环境的感知进行自动决策与执行,是具身智能的第二个难点。在 OmAgent 框架中,除了依托 VLM 模型完成任务拆分规划、调用 MCP等基础能力外,我们进一步模拟人类与外部环境的交互逻辑,创新提出 ZoomEye 树搜索算法 —— 这一算法专为增强 VLM 在高分辨率环境下的交互能力而设计,其核心思路是复刻人类观察环境时的 “缩放行为”:如同人眼会先整体扫视再聚焦细节,模型能通过类似的递进式探索,逐步深入解析环境中的关键信息。其核心创新点包括:
- 树结构图像表示:
- 分层图像建模:将图像表示为树结构,根节点代表整体图像,子节点代表父节点的缩放子区域
- 递归分割策略:根据预设分辨率限制,将图像递归分割为四个等大小的子区域
- 深度控制机制:通过节点深度控制缩放级别,实现从全局到局部的渐进式探索
- 错误恢复机制:具备处理搜索失败情况的恢复能力
- 人类视觉模拟:
- 缩放行为模拟:模拟人类观察图像时的放大和缩小操作
- 注意力引导:基于视觉线索引导搜索过程,关注相关区域
- 回溯机制:支持从当前视图返回上一级视图,探索其他感兴趣区域
- 分辨率自适应:自动适应不同输入分辨率的图像
- 置信度评估系统:
- 存在置信度(Existing Confidence):评估目标对象在当前视图中的存在概率
- 潜在置信度(Latent Confidence):评估通过进一步缩放发现目标对象的可能性
- 回答置信度(Answering Confidence):评估当前视觉信息是否足以回答问题
3. OmAgent 在行业应用中的性能评估
为了验证OmAgent在实际应用的性能效果,我们在配备 8 张 80G A100 的硬件环境下,将 OmAgent 与主流大模型在开放目标理解(open detection)、复杂事件判断(visual cognition)、复杂多媒体文档理解(doc parsing)三大行业场景中进行对比测试。
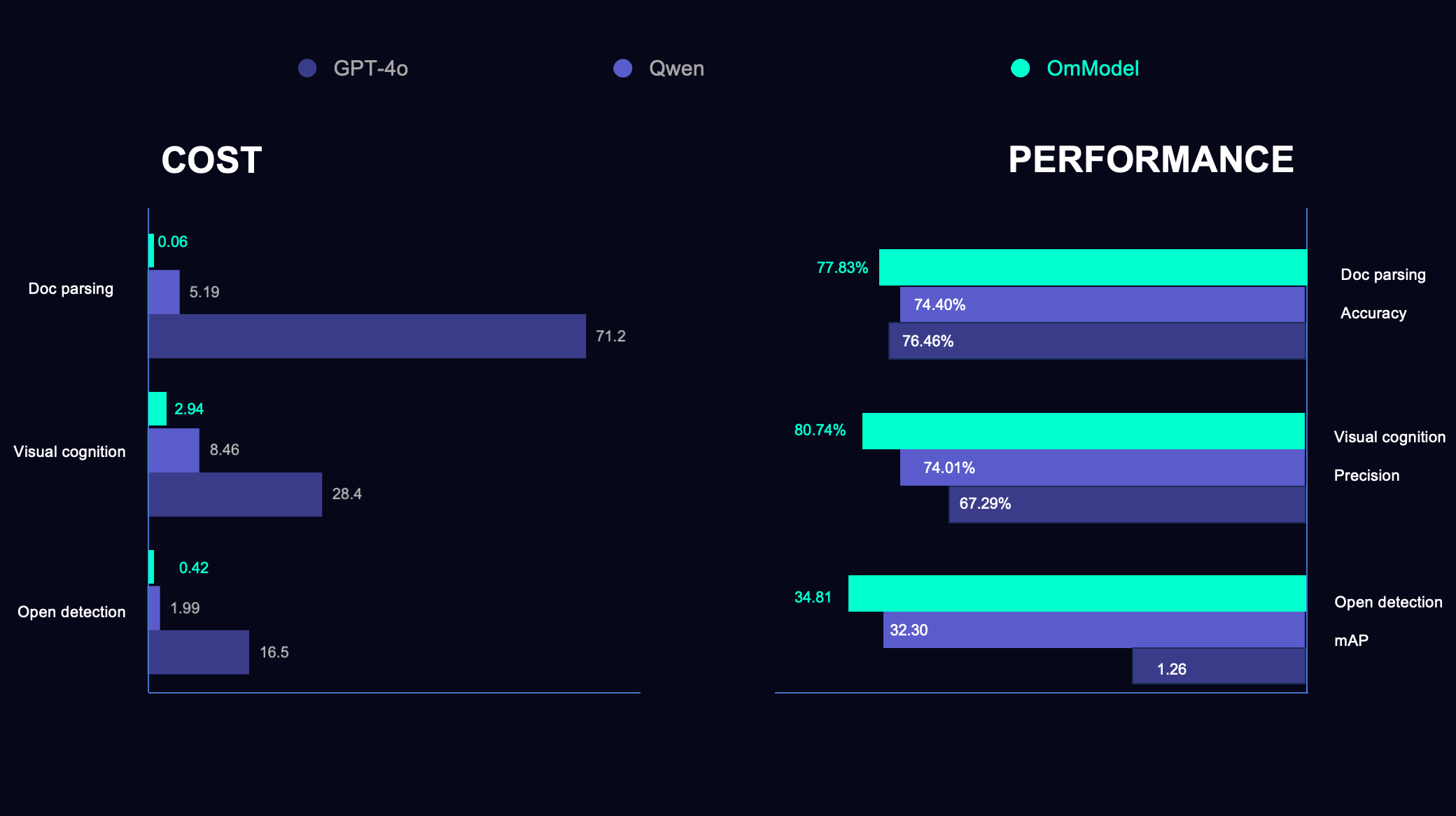
开放目标理解场景
| 模型 | 厂商 | mAP | 延迟(s/帧) | QPS | 成本(rmb/千帧) | 平均输出token |
|---|---|---|---|---|---|---|
| OmDet(1B) | Om AI | 30.80 | 0.01 | 800 | 0.02 | - |
| OmR1(3B) | Om AI | 34.81 | 1.51 | 45.73 | 0.42 | 149.25 |
| GPT-4o | OpenAI | 1.26 | 2.73 | 4.81 | 16.5 | 58.67 |
| Qwen2.5VL-32B | 阿里 | 32.30 | 3.31 | 9.68 | 1.99 | 127.39 |
在开放目标理解(open detection)任务的性能评测中,我们使用OVDEval作为评估数据集,该数据集覆盖率在开放场景下评估包括目标属性、小目标、负向目标等多元通用检测能力。首先,OmDet作为我们的超轻量级解决方案,仅使用1B参数就实现了30.80 mAP的优异成绩,同时将延迟控制在惊人的0.01秒,QPS高达800,为实时场景提供了高效解决方案。通过把强化学习引入VLM模型,OmR1可以识别更加复杂的目标与类型,通过推理的方式,达到了34.81 mAP,显著超越了其他模型,验证了强化学习方法在视觉语言模型中的潜力。另外一个值得关注的是我们在成本控制方面的突破性成果。OmDet的处理成本仅为0.02元/千页,相比GPT-4o降低了825倍, 而OmR1也以3B的模型规模将成本压缩到相比GPT-4o 降低38倍。
复杂事件判断
| 模型 | 厂商 | 精确率 | 延迟(s/帧) | QPS | 成本(rmb/千帧) | 平均输出token |
|---|---|---|---|---|---|---|
| OmR1(3B) | Om AI | 80.74% | 3.02 | 6.56 | 2.94 | 174.45 |
| Qwen2.5VL-32B | 阿里 | 74.01% | 3.77 | 2.08 | 8.46 | 31.38 |
| GPT-4o | OpenAI | 67.29% | 4.68 | 4.09 | 28.4 | 32.68 |
复杂事件判断 (visual cognition) 是面向监控场景的通用判断模型,专注于处理多类场景下的智能分析任务。在该任务中,用户可根据不同场景自定义复杂管控规则,并通过指令灵活定义复杂异常事件 —— 内置模型的智能体需依据这些定义完成环境判断、异常分析,并在图像中精准标注异常位置。在这一行业应用中,基于强化学习的OmR1模型展表现同样出色。OmR1以80.74%的精确率显著超越其他规模更大的模型。通过推理,OmR1平均输出token为174.45,在复杂推理过程中能够产生更加详细和深入的分析内容。从成本效益角度分析,OmR1的处理成本相比GPT-4o降低了近90%,在实际应用场景中展现出极强的实用价值。
复杂多媒体文档理解
| 模型 | 厂商 | 准确度 | 延迟(s/页) | QPS | 成本(rmb/千页) |
|---|---|---|---|---|---|
| OmDoc(1B) | Om AI | 77.83% | 0.27 | 299.2 | 0.06 |
| Qwen2.5VL-32B | 阿里 | 74.40% | 4.56 | 3.71 | 5.19 |
| GPT-4o | OpenAI | 76.46% | 8.16 | 0.836 | 71.2 |
复杂多媒体文档理解(doc parsing)任务主要针对包含表格、图表等结构关系复杂复杂长文档进行解析,记忆存储,及相关问题解答的能力。OmDoc这一文档智能体应用展现出了显著的技术优势。从性能数据来看,OmDoc在准确度上达到77.83%,超越了其他更大规模的模型,在保持高精度的同时实现了全面的性能领先。在效率方面,OmDoc将处理延迟控制在0.27秒,相比Qwen2.5VL-32B提升了17倍,相比GPT-4o提升了30倍,这种毫秒级的响应速度为实时文档分析应用提供了坚实的技术基础。在吞吐量表现上,OmDoc的QPS达到299.2,为大规模批处理场景提供了强有力的技术支撑。更为突出的是OmDoc在成本控制方面的卓越表现,处理成本仅为0.06元/千页,相比GPT-4o的71.2元/千页更是降低了1187倍。
4. 开源贡献:构建AI 智能技术生态
同时,我们始终坚信技术的生命力源于生态共建。为此,我们将核心技术体系向开源社区全面开放,并受到社区的强烈反响,在github 累计收获超 9K star。
- VLM-R1强化学习框架:https://github.com/om-ai-lab/VLM-R1
- ZoomEye树搜索算法:https://github.com/om-ai-lab/ZoomEye
- OmAgent 多模态智能体框架:https://github.com/om-ai-lab/OmAgent
- OmDet 开放视觉感知:https://github.com/om-ai-lab/OmDet
- OmChat 视觉语言交互:https://github.com/om-ai-lab/OmChat
5. 展望
智能终端的进化之路,从来不是单一模型能够独当一面的坦途,其需兼顾环境复杂性、任务多样性、与交互关联性。我们的愿景是,以 OmAgent 为技术中枢,为未来的每一个智能终端注入「完整的智能人格」。我们期待看到,物理世界中的所有终端都能突破当前的功能边界,蜕变为自主感知、主动决策、持续进化的具身智能体。让智能体在工业安全生产管理、医疗诊断等各种领域大显身手,让 AI 走出数据中心,深度融入物理世界,成为产业升级与生活变革的核心驱动力。
更多技术细节和开源项目,请访问:Om AI Lab GitHub
技术交流与合作,欢迎联系我们。