引言
很多视频模型是在用户提出问题之后才真正 "开始看" 视频:先拿到一段完整视频,再抽帧、编码、送入模型推理。但真实设备不是这样运行的。摄像头持续采集,机器人持续移动,屏幕内容持续变化,用户的问题也可能在任意时刻到来。面向这些场景,模型不应该等到提问出现后才从头理解画面。
VLX-Flow 面向的正是这种在线视频理解问题。它把视频作为连续到来的流式片段处理,在推理过程中增量更新模型内部记忆;当交互发生时,模型直接基于已经维护好的状态回答,而不是为每一次问题重新处理完整历史。
过去许多视频理解系统默认的是离线流程:先收集视频,再采样或编码,最后让模型在这些帧上完成推理。这个范式适合很多基准测试式任务,但真实环境需要的是另一种能力:模型能否随着世界变化,持续维护一个演化中的视觉状态。VLX-Flow 将视频理解视为一个连续过程。新的片段到来时被逐步吸收,内部记忆在推理过程中更新,后续问题则从这个累积状态中获得回答。
一、流式视频理解与交互
这一节先回答 VLX-Flow 的核心问题:模型如何持续、实时地 "看见" 视频世界,并把不断到来的画面转化为可复用的内部状态。
目前主流的视频理解 VLM 通常有两种做法:全帧输入把整段视频切成一堆帧,一次性喂给模型,缺点是计算量极大、延迟高、长视频很难跑;固定采样每隔几秒抽一帧,只给模型看这些离散画面,缺点是容易丢失动作细节——比如一个人拿起杯子的瞬间,可能刚好落在两帧之间的缝隙里。更关键的是,这两种方式本质上都是 "离线问答":用户提问时,模型才开始处理视频。这不适合摄像头、机器人、屏幕录制等在线场景——视频是连续的,但理解是断断续续的。
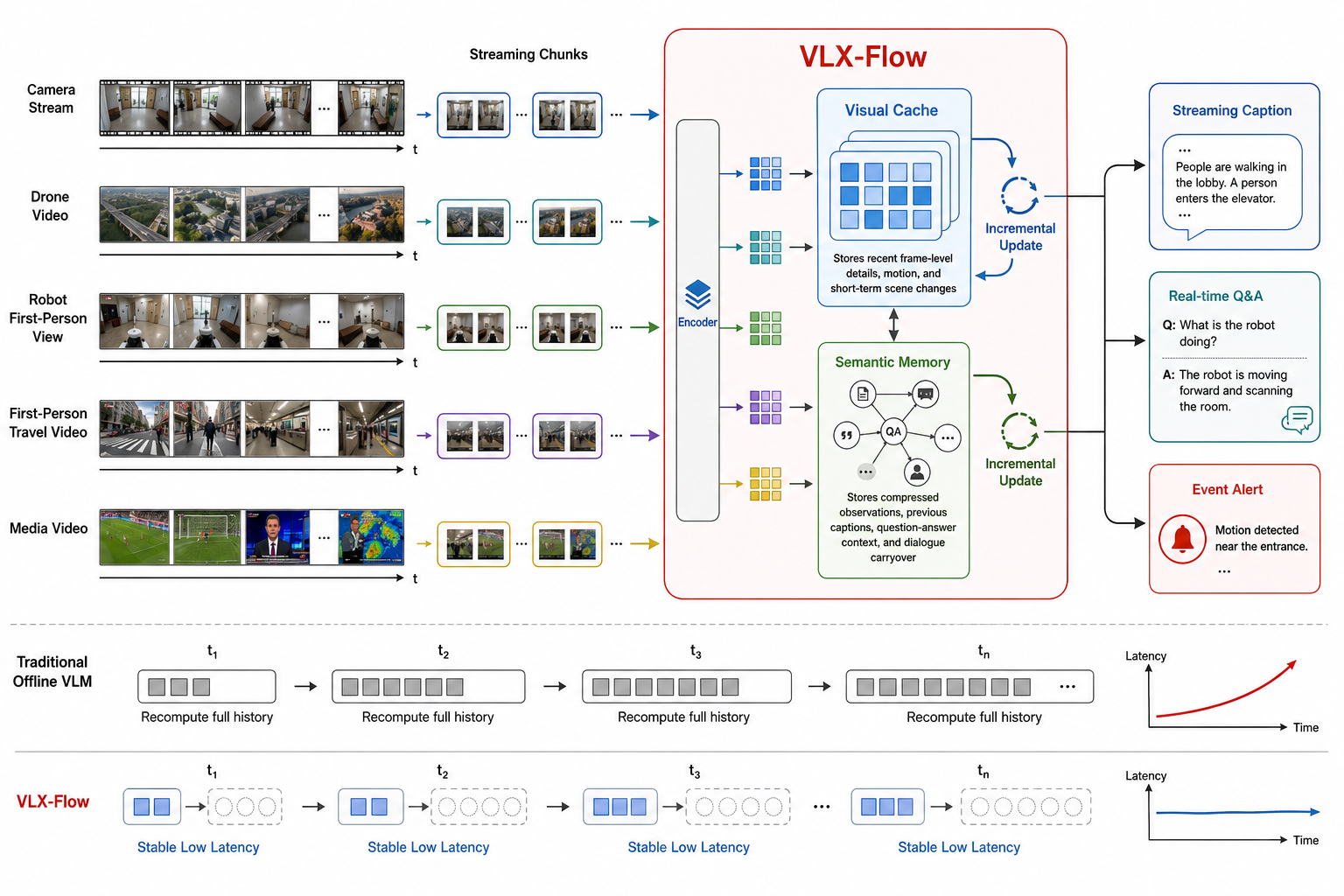
1. 流式输入:从视频文件变成视觉状态
VLX-Flow 的目标是让模型在推理过程中持续更新视觉上下文,而不是事后总结。视频被拆成连续的小片段(每个片段若干帧),像水流一样依次进入模型。视觉侧负责将新片段编码成语言模型可用的特征;语言模型侧维护一个可复用的缓存状态。新片段到来后,模型基于当前状态做增量更新,而不是把整个历史重新算一遍。旧信息不会被简单丢弃,也不会无限堆叠成超长上下文——它们被压缩成状态,而不是复制成历史。
这个缓存承担了 "视觉记忆" 和 "语义记忆" 的角色:保留当前场景、主体、动作变化和最近的交互历史。后续问答时,模型能直接从中知道 "刚才发生了什么"。
举个例子:画面里一个人先拿起杯子,再走向门口,最后把杯子放在桌上。传统的固定采样可能只捕捉到 "拿着杯子" 和 "放在桌上" 两个孤立瞬间,中间的动作链路断了。VLX-Flow 会持续维护这条动作链路。用户随后问 "他刚才把什么放在桌上?" ——模型可以从缓存状态中恢复事件关系。
2. 推理链路:双层记忆支撑在线交互
语言模型部分包含 Linear Attention 模块。标准自注意力机制随序列变长会需要越来越大的 KV 缓存,导致显存和计算量快速增长。Linear Attention 则不同,它可以通过可递推的状态来保留历史信息,每次只做增量计算。带来的直接好处:
- 延迟更可控——视频流不断进入时,系统不需要每次都重算完整历史,首 token 时间和连续交互延迟更稳定。
- 显存增长更平缓——长视频的理解瓶颈通常不在单帧编码,而在历史状态的累积,Linear Attention 让模型能在更长时间窗口内保持语义连贯,同时减轻显存压力。
在此基础上,VLX-Flow 把在线记忆拆成两层:视觉缓存保留最近时间窗口中的画面细节(动作、位置、短时变化);语义记忆沉淀已经生成过的连续描述、用户问题和回答,作为可引用的语义历史。前者保证实时细节不丢,后者保证长程语义不散。
多轮交互时,语义记忆不是简单地把文本越拼越长,而是会在合并、裁剪或回放时同步模型内部缓存,避免文本历史与模型实际记忆状态之间出现错位。
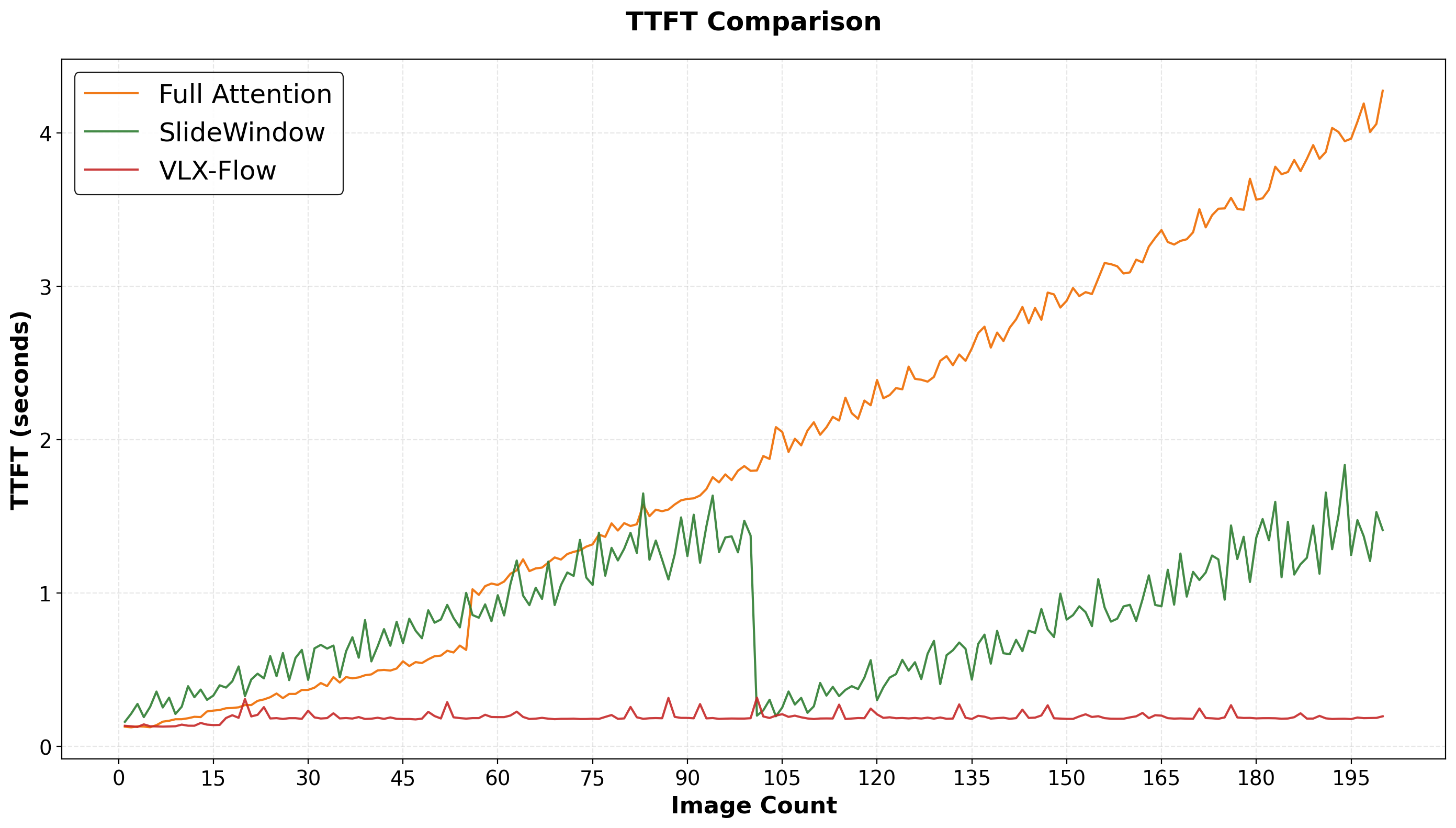
首 token 生成时延(TTFT)随输入图像数量变化的趋势对比。Full Attention(橙色)随着历史上下文变长持续上升;SlideWindow(绿色)通过窗口重置限制历史长度,因此呈现“上升-重置-再上升”的波动趋势;VLX-Flow(红色)通过双层记忆机制压缩历史状态,使 TTFT 在长序列下仍保持较低且稳定。
3. 任务能力:先观察、后提问
VLX-Flow 首先支持连续视频描述。这里的描述不是单帧画面描述,而是一种面向流式推理的语义记忆。模型在视频持续进入的过程中,将场景、主体、动作、物体状态、镜头变化等关键信息逐步写入可复用的语义记忆。每一段描述都不是从零开始,而是接续此前的视频状态。
为了训练这种能力,我们设计了一套专门的流式理解数据范式:以短视频窗口为基本单元,每个片段对应一句简洁、客观、与视觉内容严格对应的流式 caption。模型按时间顺序依次看到这些片段,在后续某个时间点给出问题,模型必须基于此前累积的记忆回答,而不能回头重看视频。
这种设计把 "观察" 和 "回答" 显式拆开,本质上把视频理解从静态的 "片段级监督" 变成了时间递推的 "记忆监督":stream_memory 监督模型如何压缩视觉历史,question 监督该历史能否支持有效推理。
具体到任务层面,模型支持以下能力:
- 实时视频问答——用户可在视频播放或摄像头运行中直接提问( "画面里有几个人?" "刚才谁离开了?" ),模型使用已维护的流式上下文回答。
- 事件触发式交互——VLX-Flow 可以持续观察某类事件,例如人员进入、物体遗留、异常动作;一旦当前缓存状态满足触发条件,系统就可以生成提醒,而不是等用户事后查询。
二、工程价值:面向端侧的持续理解
从工程角度看,VLX-Flow 把视频理解从 "请求式 API" 变成了 "持续运行的感知模块"。如果每次提问都把视频上传到云端重新解析,系统会同时面临带宽、延迟、隐私和成本问题。VLX-Flow 更适合部署在端侧或边缘节点:视频流在本地持续编码,缓存状态增量更新,只有需要回答、触发提醒或结构化输出时才调用语言生成。
摄像头不会每隔 5 秒才 "看一眼" 世界——它一直在看。模型也应该如此。机器人也不是只在用户提问时才观察环境;它们需要持续感知、持续更新状态,并在合适的时刻把视觉理解转化为语言或行动。
因此,VLX-Flow 的核心不在于 "能不能看视频",而在于视频信息能否以流式方式进入模型,并被模型长期、低延迟、可交互地使用。
更多技术细节和开源项目,请访问:om-ai-lab/VLX-Flow。