Introduction
Most video models start watching only after a user asks a question. Real devices do not work that way: cameras keep recording, robots keep moving, screens keep changing, and queries can arrive at any time. A model for these scenarios should not wait until a query arrives before it begins to understand the scene.
VLX-Flow is designed for this online setting. It processes video as a sequence of streaming chunks, updates model memory incrementally, and answers from the maintained state instead of reprocessing the entire video history for every interaction.
Many video understanding systems still assume an offline workflow: collect the video first, sample or encode it, then ask the model to reason over the resulting frames. That works for many benchmark-style tasks, but live environments require something different. The harder problem is whether a model can maintain an evolving visual state as the world changes. VLX-Flow treats video understanding as a continuous process. New chunks are absorbed as they arrive, internal memory is updated during inference, and later questions are answered from this accumulated state.
From Offline Video QA to Streaming Understanding
The core question behind VLX-Flow is: how can a multimodal model keep understanding a video stream, rather than starting from zero only after a user asks a question?
Most video VLMs are built around one of two input strategies. Full-frame input feeds many frames from the whole video into the model at once. It preserves more information, but it is expensive, high-latency, and difficult to scale to long streams. Fixed sampling is cheaper, but it only gives the model sparse snapshots. Important actions can easily fall between sampled frames. If a person picks up a cup between two samples, the model may see the before and after states but miss the action itself.
Both approaches are useful, but they are still fundamentally offline. The model begins to process the video after the request is made. For cameras, robots, screen recordings, and edge devices, this creates a mismatch: the video is continuous, but the model's understanding happens in disconnected bursts.
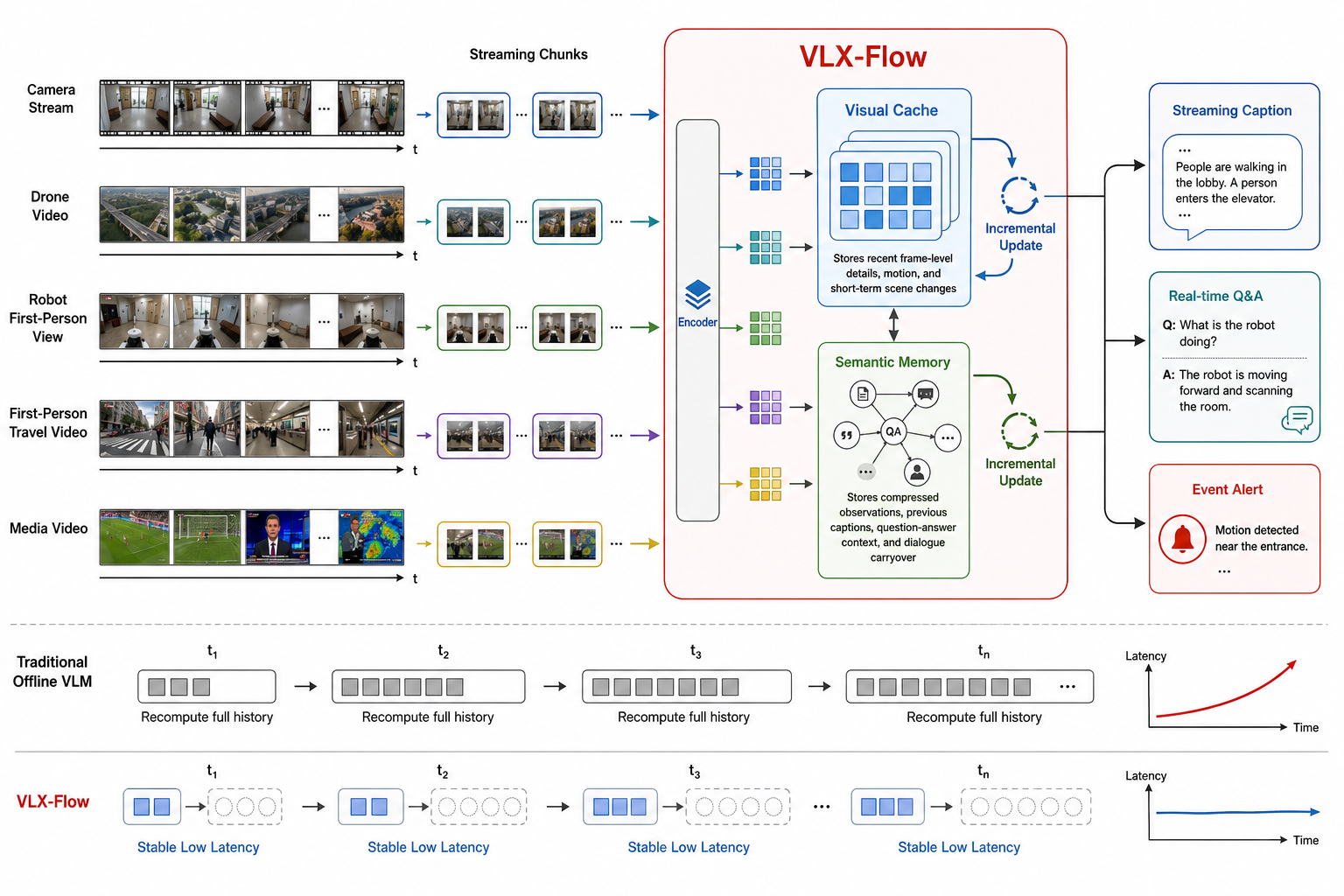
Streaming Input: Turning Video into Model State
VLX-Flow presents video to the model as a stream rather than a single static request. The stream is divided into short, consecutive chunks, and each chunk is processed in temporal order. The visual encoder converts the new frames into model-readable features, while the language model maintains a reusable internal state.
When a new chunk arrives, VLX-Flow updates this state instead of rebuilding the full context. Past information is neither discarded nor allowed to grow into an unbounded raw history. It is compressed into state rather than copied as history.
Consider a simple event: a person picks up a cup, walks toward a door, and later places the cup on a table. Sparse sampling may only capture isolated snapshots. VLX-Flow is designed to preserve the event chain across chunks, so a later question such as "What did the person put on the table?" can be answered from the maintained state.
Two-Layer Memory for Online Interaction
The language model uses Linear Attention components. With standard self-attention, longer sequences require a growing KV cache, so memory and computation increase as the stream gets longer. Linear Attention can carry history through a recurrent state and update it incrementally, giving the model a natural mechanism for stream-oriented inference.
This gives VLX-Flow two practical advantages:
- More stable latency: the model does not need to recompute the entire history for every new interaction.
- Smoother memory growth: long streams can preserve semantic continuity without letting historical context grow without bound.
VLX-Flow builds on this with two complementary memory layers. The visual cache keeps recent visual details such as actions, object positions, and short-term scene changes. The semantic memory stores higher-level context, including streaming descriptions, user questions, model answers, and dialogue context. The visual cache protects short-term detail; the semantic memory keeps the longer narrative coherent.
For multi-turn interaction, this memory cannot be treated as a simple text transcript. When text history is merged, trimmed, or replayed, VLX-Flow synchronizes the model's internal cache so that the visible conversation and the actual model state do not drift apart.
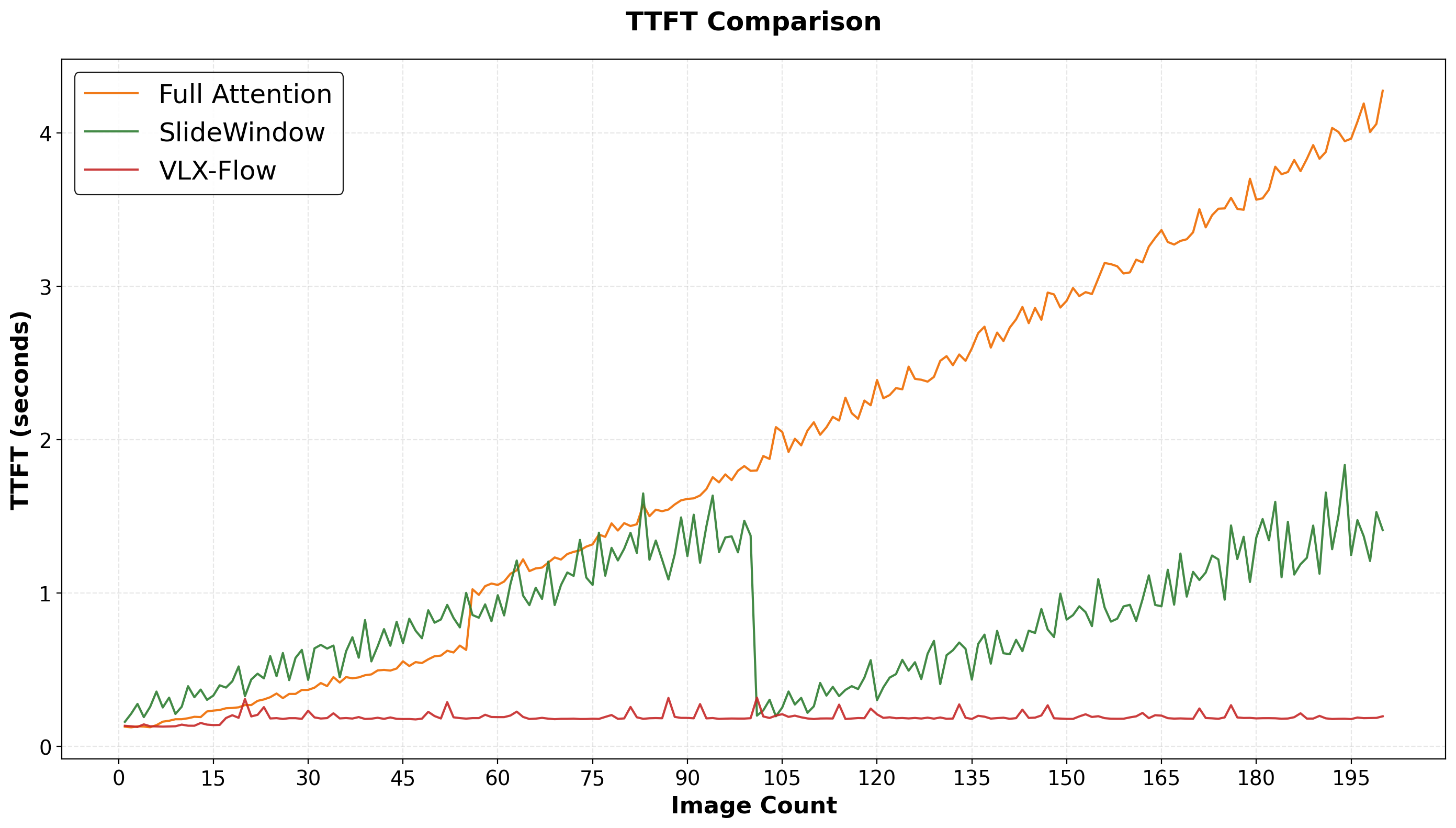
Time to first token (TTFT) as the number of input images increases. Full Attention (orange) rises steadily as the historical context grows. SlideWindow (green) limits history with window resets, producing a rise-reset-rise pattern. VLX-Flow (red) compresses history through its two-layer memory mechanism, keeping TTFT low and stable over long sequences.
Observe First, Ask Later
One core capability of VLX-Flow is continuous video description. The generated descriptions are not isolated single-frame descriptions. They act as semantic memory for streaming inference. As video flows in, the model records useful information about the scene, subjects, actions, object states, and camera changes. Each description continues from the previous state rather than starting over.
We formulate this as a streaming understanding data format. A short video window is divided into chronological chunks, and each chunk is paired with a concise, visually grounded streaming description. Later, a question is introduced, and the model must answer from the memory it has accumulated so far rather than going back to rewatch the video.
This separates observation from answering. Instead of static segment-level supervision, the supervision becomes recursive over time: streaming descriptions teach the model how to compress visual history, while question answering tests whether that memory can support reasoning.
This supports several online video workflows:
- Real-time video question answering: users can ask questions while a video is playing or a camera is running, such as "How many people are in the scene?" or "Who just left?" The model answers from the maintained streaming context.
- Event-triggered interaction: the system can monitor conditions such as a person entering, an object being left behind, or an anomalous action, and generate an alert when the maintained state satisfies the trigger.
Engineering Value: Continuous Understanding at the Edge
From an engineering perspective, VLX-Flow changes video understanding from a request-based API into a continuously running perception module. If every question requires uploading video to the cloud and reanalyzing the full history, the system pays a combined price in bandwidth, latency, privacy exposure, and compute cost.
VLX-Flow is a better fit for on-device and edge scenarios. Video streams can be encoded locally, memory can be updated incrementally, and language generation only needs to run when the system must answer a question, trigger an alert, or produce structured output.
A camera does not look at the world once every five seconds. It is always watching. Models built for real devices should work the same way. VLX-Flow is about making video usable as a live, long-lived model context, not just as another uploaded file.
For more technical details and open-source projects, please visit: om-ai-lab/VLX-Flow.