摘要
当多模态大模型(VLM)开始进入真实场景的摄像头、无人机和具身机器人,单纯讨论“模型有多聪明”已经不够了。机器人不仅需要知道“画面里有什么”,更需要准确知道“它在哪里”。
然而,当前的主流 VLM 虽然在图像全局场景理解上表现优异,但在需要精确定位的细粒度感知任务上往往表现不佳。为了弥补这一短板,我们推出了 VLX-Seek。它作为一个面向端侧具身视觉的高效推理模型,将 VLM 的能力从“看懂”直接推向了“精准定位”。
一、VLM 为什么看得懂,却不一定看得准?
通用 VLM 的优势在于语义理解和语言推理。它们可以描述图片内容,回答视觉问题,理解复杂指令,也能在一定程度上完成视觉推理。但精确定位是另一类问题:定位不仅要求模型知道“这是什么”,还要求模型判断“它在哪里”“边界到哪里”“有几个实例”“哪一个目标符合这段描述”。这类任务依赖更强的局部细节、空间结构和实例区分能力。
传统 VLM 常见的定位方式,是让语言模型直接生成坐标,例如 [x1, y1, x2, y2]。这个形式看起来简单,实际却很脆弱。坐标不是自然语言,LLM 更擅长生成词语、短语和句子,而不是稳定地产生精确数值。一个框有四个坐标,多个框就会变成更长的数字序列。坐标顺序、归一化范围、标点格式、目标数量,只要任何一处出错,最终结果就可能无法解析,或者框的位置明显偏离目标。
多目标检测会进一步放大这个问题。一个目标需要生成四个坐标,十个目标就意味着几十个坐标 token。目标越多,输出越长,模型越容易漏掉目标,也越容易在格式上出错。更重要的是,长坐标序列会直接拖慢解码过程:每多生成一个坐标 token,模型都要多走一步自回归推理。对于云端离线分析,这可能只是多等一会儿;但在机器人、无人机、摄像头和边缘终端等具身端侧场景中,定位结果往往要实时反馈给导航、抓取、避障或交互模块,推理效率本身就是核心指标。坐标生成式 VLM 在多目标场景下会把大量输出预算花在数值坐标上,而不是更快地完成目标选择和空间决策。
因此,问题的本质不是 VLM 完全“不会看图”,而是精确定位这种任务形式,和语言模型的生成方式并不天然匹配。VLX-Seek 换了一个角度:不要让模型凭空生成框,而是让模型理解候选区域,并在这些区域之间做选择。
二、核心思路:从坐标生成到区域指代
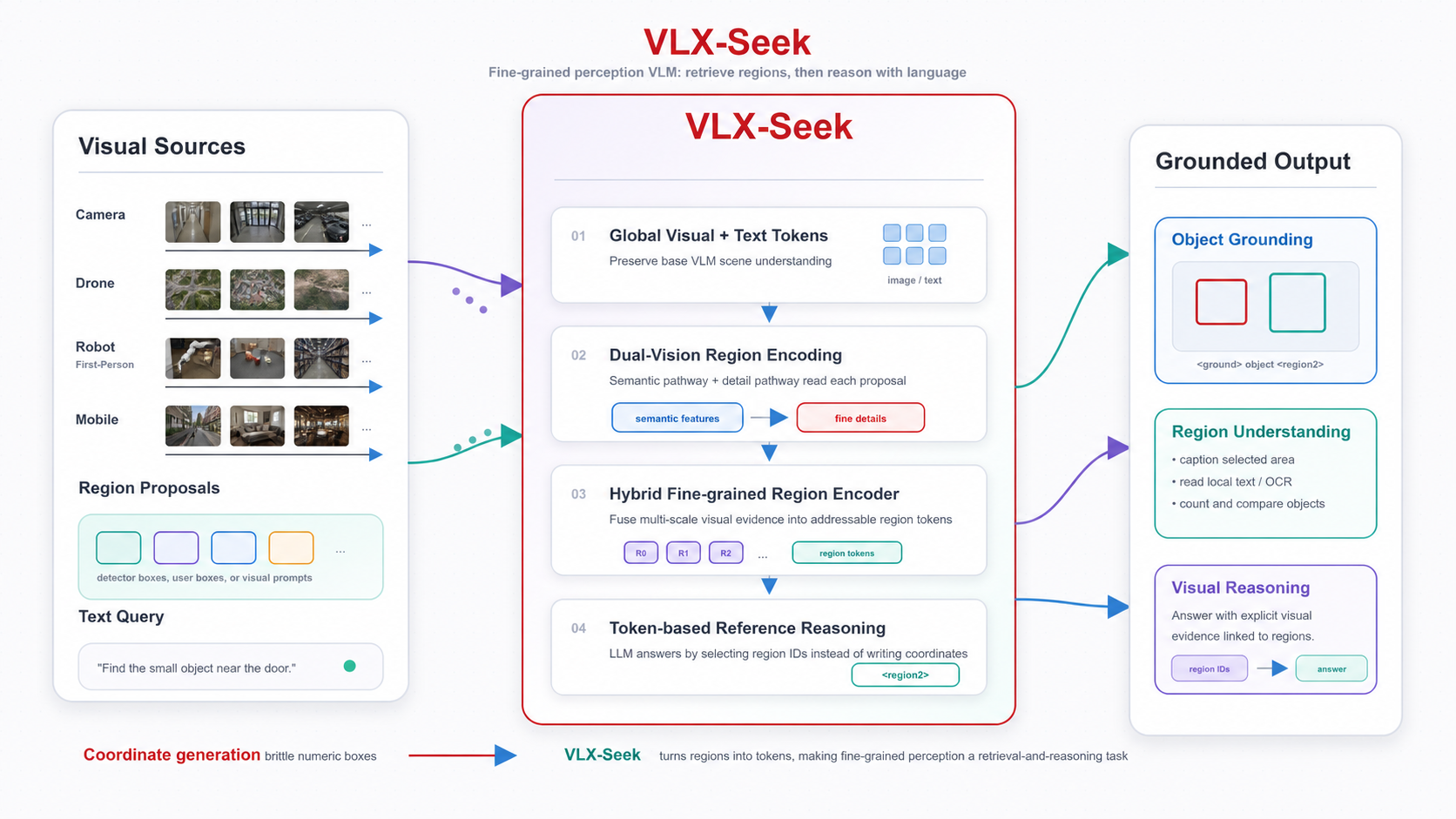
VLX-Seek 的核心范式可以概括为一句话:把以对象为中心的感知任务,从坐标生成问题,改写成特征检索和区域引用问题。也就是说,模型不再只接收全图视觉 token 和文本 token,而是额外接收一组可寻址的区域 token。每个区域 token 都对应图像中的一个候选区域,模型可以像引用文本实体一样引用这些视觉区域。
例如,输入中可以包含 <region0>、<region1>、<region2> 这样的区域索引,以及它们对应的区域 token。当用户问“穿红衣服的人在哪里”时,模型不需要从零开始生成坐标,而是判断哪个区域 token 最符合描述,然后输出对应的区域索引。这样,定位任务就不再是“生成精确几何数字”,而是变成了“在候选视觉区域中做语言条件检索”。
这种形式更符合 LLM 的能力边界。语言模型本来就擅长比较、选择、指代、解释和推理;VLX-Seek 则把候选区域提前编码成它能处理的 token,让定位能力进入语言模型更自然的工作方式。这个变化看似简单,但影响很大:检测、指代表达理解、区域描述、区域问答和目标计数,都可以统一到“区域引用”这个框架中。模型不再只是说“画面里有一个人”,而是可以进一步指出“是这个区域里的这个人”。
三、推理链路:先召回区域,再把区域变成 token
VLX-Seek 的推理链路可以分成三步。第一步是生成候选区域,系统先通过候选区域生成网络(Omni Proposal Network,简称 OPN)召回图像中可能包含前景目标的区域。这一步并不负责最终判断目标类别,而是尽可能把图像中有意义的对象区域找出来,为后续语言模型的推理提供明确的视觉候选。VLX-Seek 的设计是解耦的,候选区域生成网络并不和 VLM 主体强绑定。实际应用中,它可以替换为其他检测器,也可以直接使用人工指定的感兴趣区域。
第二步是把候选区域编码成区域 token。候选框本身只是一个几何范围,它告诉模型“这里有一个区域”,但还没有告诉模型“这个区域里是什么”“它和其他区域有什么区别”“它是否符合用户的文本描述”。因此,VLX-Seek 使用混合细粒度区域编码器 HFRE,从候选框中提取区域级视觉特征,并将这些特征投影到 LLM 的嵌入空间。经过这一步,区域就不再只是坐标,而变成了语言模型可以读取、比较和引用的视觉表示。
第三步是让 LLM 基于区域 token 完成推理。模型输入不再只有全局图像 token 和文本 token,还会插入带有编号的区域 token,例如 <region0>、<region1>、<region2>。用户可以用自然语言描述目标,模型则通过区域索引完成定位和回答。这套机制把定位任务转化成了更稳定的区域指代任务:模型不再凭空生成坐标,而是在显式候选区域中进行选择、组合和解释。
四、HFRE:让区域 token 同时拥有语义和细节
VLX-Seek 的核心组件是 HFRE,也就是混合细粒度区域编码器。它要解决的问题是:单一视觉编码器很难同时满足“语义对齐”和“细粒度空间感知”。通用 VLM 原始的视觉编码器通常已经和语言模型完成对齐,擅长提供全局语义信息。它知道图像大概是什么,目标可能属于什么类别,也能支持高层理解。但这类编码器往往不是为精细检测训练的,对小目标、边界、局部纹理和多尺度区域的表达并不充分。
检测类或高分辨率视觉编码器则相反。它们对局部细节、边缘、纹理和空间结构更敏感,但未必天然处在 LLM 可以直接理解的语义空间中。VLX-Seek 的方案,是把两种能力结合起来:主视觉编码器保留原始 VLM 的语义对齐能力,让模型知道一个区域“像什么、可能是什么”;辅助视觉编码器则提供更高分辨率的局部细节,让模型看到边界、纹理、小目标和区域差异。
随后,SimpleFP 模块会为 ViT 类视觉特征补足多尺度表达。真实图像里的目标大小差异很大,同一张图中可能既有占据大面积的人,也有很小的手机、杯子或标识牌。单尺度特征很难同时处理这些目标,多尺度结构可以让模型更好地适应不同大小的候选区域。接着,VLX-Seek 会根据候选框从视觉特征图中抽取区域特征,相当于把“整张图的视觉信息”切分成“一个个候选目标的视觉信息”。最后,区域-语言连接器会把区域特征投影到 LLM 的嵌入空间,让一个候选框真正变成语言模型可以读取、引用和推理的区域 token。
这套结构的核心价值,是让区域 token 同时携带两类信息:一类是高层语义,另一类是细粒度空间细节。对于普通 VQA 来说,模型知道“这是一辆车”可能就够了;但对于开放词汇检测和具身任务来说,模型还必须知道“是哪一辆车”“车在画面哪里”“它和旁边目标的边界如何区分”。这正是 HFRE 要补上的能力。
五、区域引用机制:让视觉区域变成可被语言引用的对象
VLX-Seek 不是简单地把区域特征塞进模型,而是设计了一套基于 token 的区域引用机制。在输入侧,每个区域都有一个显式编号。例如,第 0 个候选区域对应 <region0>,第 1 个候选区域对应 <region1>,第 2 个候选区域对应 <region2>。这些区域编号会和对应的区域 token 一起进入语言模型,使 LLM 能够把区域特征和区域编号绑定起来。
在输出侧,模型可以通过特殊 token 表达视觉定位关系。例如,The <ground>people</ground><object><region2><region10></object> are dancing. 这表示文本中的 “people” 对应图像中的 <region2> 和 <region10>。通过这种方式,模型输出的不是一串容易出错的坐标数字,而是更稳定、更容易解析的区域引用。更重要的是,区域引用通常比坐标生成更短:模型只需要输出对应的区域索引,而不必为每个目标逐个生成 [x1, y1, x2, y2] 这样的坐标序列。目标数量越多,这种差异越明显,也就意味着更少的输出 token、更低的解码开销和更快的推理速度。
这套机制带来四个直接好处。第一,定位结果更稳定,因为模型输出的是区域索引,而不是精确数值坐标。第二,推理链路更清晰,模型可以先理解文本描述,再判断对应区域,最后输出可解析的区域引用。第三,推理速度更快,尤其是在多目标检测和计数场景中,区域索引输出比长坐标序列更轻量。第四,任务形态更统一,检测、指代表达理解、区域描述、区域问答和计数,都可以在同一套区域 token 框架下完成。
这也是 VLX-Seek 相比普通检测增强 VLM 的关键区别:它不是简单给 VLM 外接一个检测头,而是把区域作为一种新的视觉语言实体引入模型。换句话说,VLX-Seek 让图像中的目标获得了类似“语言实体”的地位。模型不仅能描述它,还能引用它、比较它、推理它;同时,由于输出形式从长坐标序列变成了紧凑的区域索引,系统在复杂多目标场景下也更容易保持较高的推理效率。
六、两阶段训练:先对齐区域,再强化感知
VLX-Seek 的训练采用两阶段策略,目标是在增强细粒度感知能力的同时,尽量不破坏模型本身的通用能力。第一阶段是区域-语言对齐。这个阶段的重点,不是让模型立刻学会所有检测和感知任务,而是先让新增的区域 token 对齐到 LLM 的特征空间。训练时会冻结主干 VLM 的主要参数,把学习压力集中在 HFRE、区域-语言连接器和新增特殊 token 上。这样做的好处是,模型可以先稳定理解“一个区域 token 对应一个视觉区域”,也就是先学会把视觉区域接入语言模型,再去处理更复杂的感知指令。
第二阶段是感知指令微调。这一阶段会引入更丰富的感知任务,包括检测、引用表达理解、区域描述、区域推理、计数和 OCR 等,让模型在真实指令中学习如何使用区域 token。这里的关键不是单纯堆数据,而是同时避免两个风险:一是增强细粒度感知后损伤原有通用视觉理解能力,二是模型在目标不存在时仍然幻觉式地给出答案。
第一个风险对应的是灾难性遗忘。VLM 模型本身原本已经具备图像问答、描述和常识推理等能力,如果训练过程过度偏向检测任务,可能会损伤这些通用能力。因此,训练中会混入常规 VLM 指令数据,用来保持模型原有的视觉语言能力。第二个风险对应的是开放词汇检测中的拒识能力。真实场景的难点不只是“找到存在的东西”,还包括“不要把不存在的东西找出来”。因此,训练中会加入拒识样本,让模型面对不存在的目标时学会回答“没有”,而不是强行指向某个区域。
这也是 VLX-Seek 比单纯检测增强方案更完整的地方。它不仅学习“如何找到目标”,也学习“什么时候不该找”。
七、能力结果:小参数模型补上细粒度感知短板
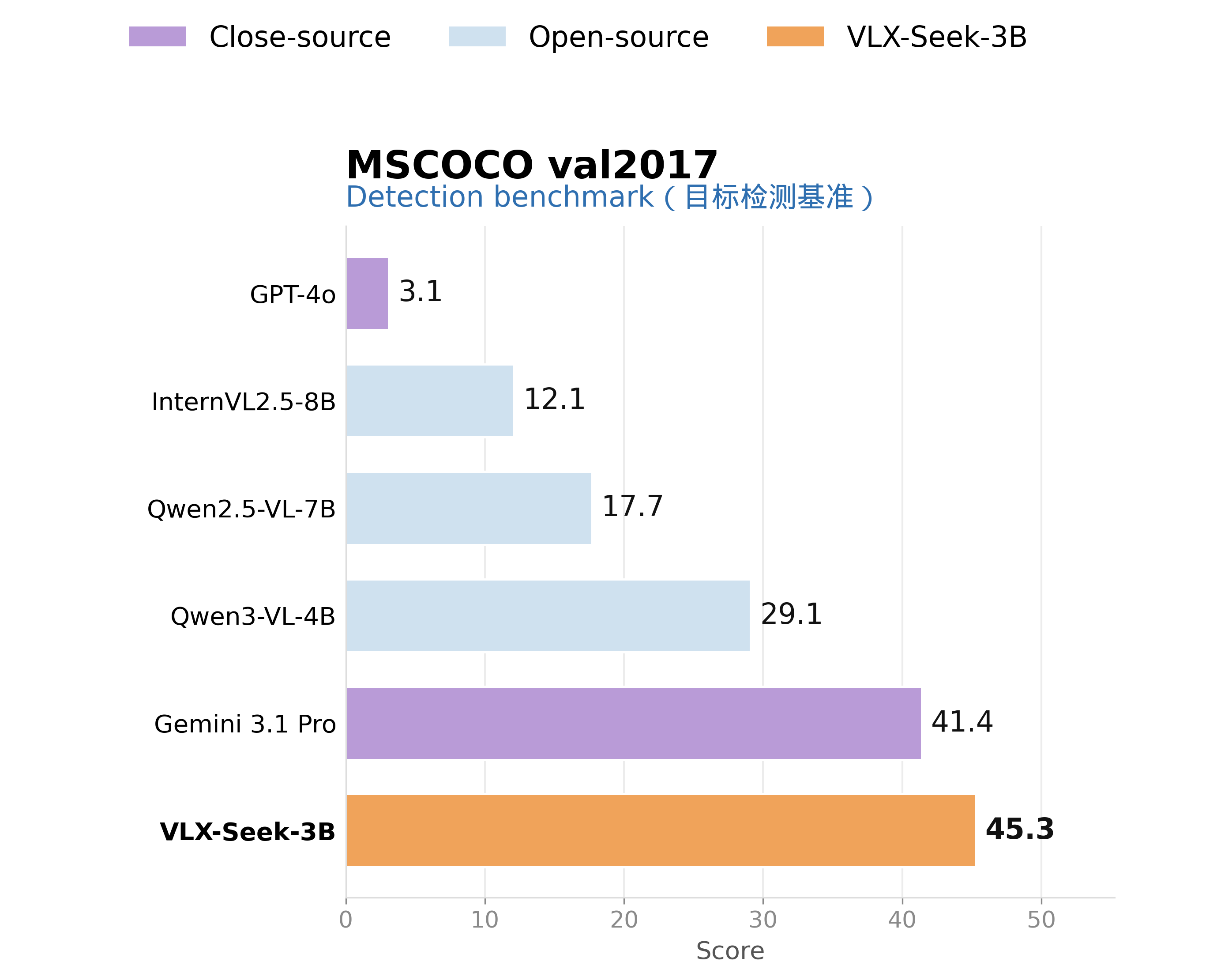
从实验评测看,VLX-Seek-3B 在多个细粒度感知任务上已经展现出明显优势。在通用目标检测上,VLX-Seek-3B 在 COCO 检测任务中达到 45.3 mAP,高于 Qwen2.5-VL-7B 的 17.7,也高于 Gemini 3.1 Pro 的 41.4。这说明它并不是只在语言推理上更强,而是确实补上了 VLM 在区域级定位上的短板。
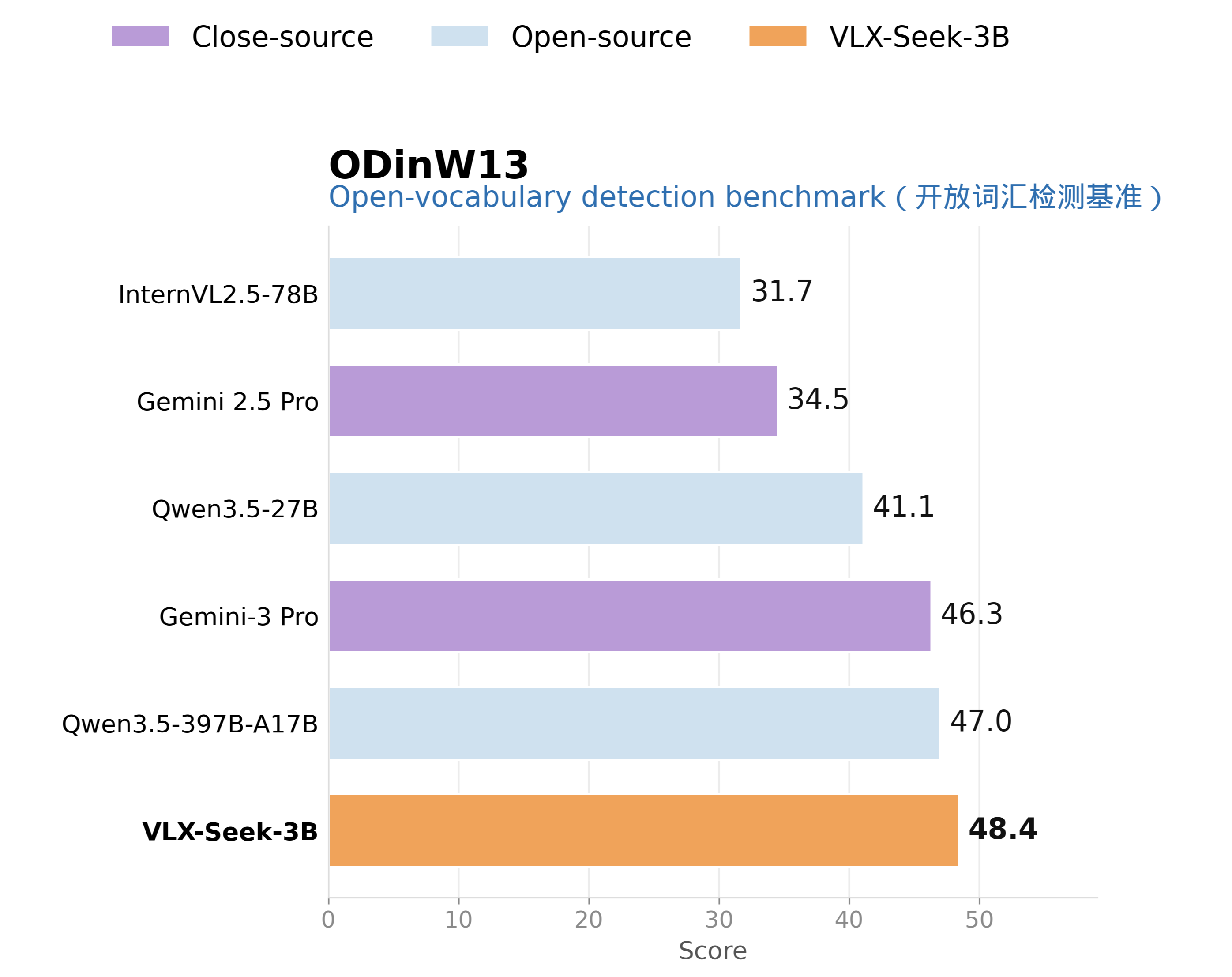
在开放词汇检测上,VLX-Seek-3B 在 OVDEval 上达到 43.7。OVDEval 的难点在于,它不仅要求模型识别开放类别,还包含更复杂的语言标签和难负样本。换句话说,模型要能区分“真正符合描述的目标”和“看起来相似但并不符合描述的目标”。VLX-Seek 在这个任务上的表现,说明区域 token 机制不仅能做普通检测,也能结合 VLM 的语言理解能力处理更复杂的开放语义定位。
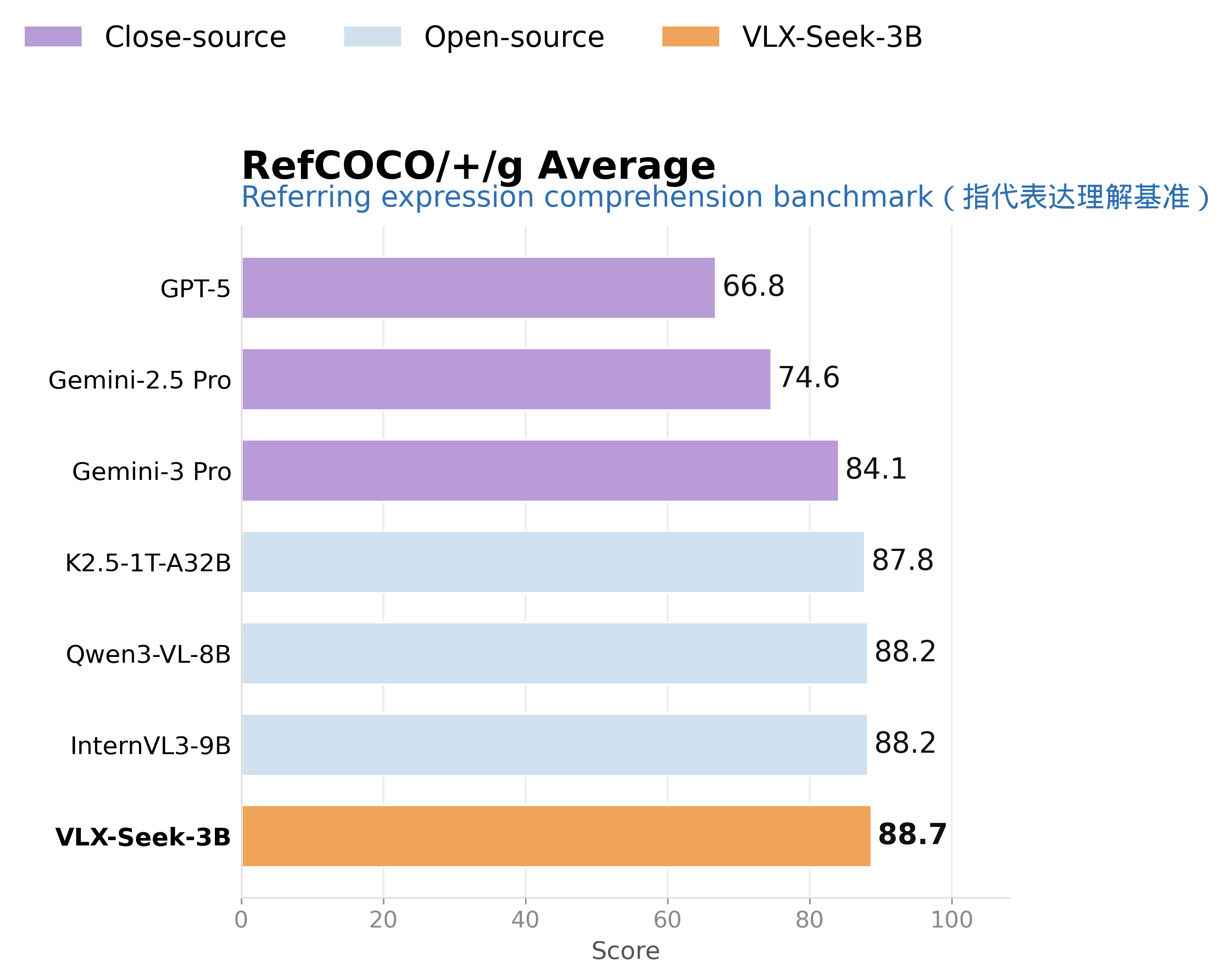
在复杂指代表达任务上,VLX-Seek-3B 在 RefCOCO 系列任务中的平均表现达到 88.7,高于 Gemini 3 Pro 的 84.1,也高于 Qwen3-VL-8B 的 88.2。这个结果说明,它不仅能找常见类别目标,也能理解更复杂的自然语言描述,例如“左边第二个穿黑色衣服的人”“靠近桌子的那只杯子”“被另一个物体遮住一部分的目标”。
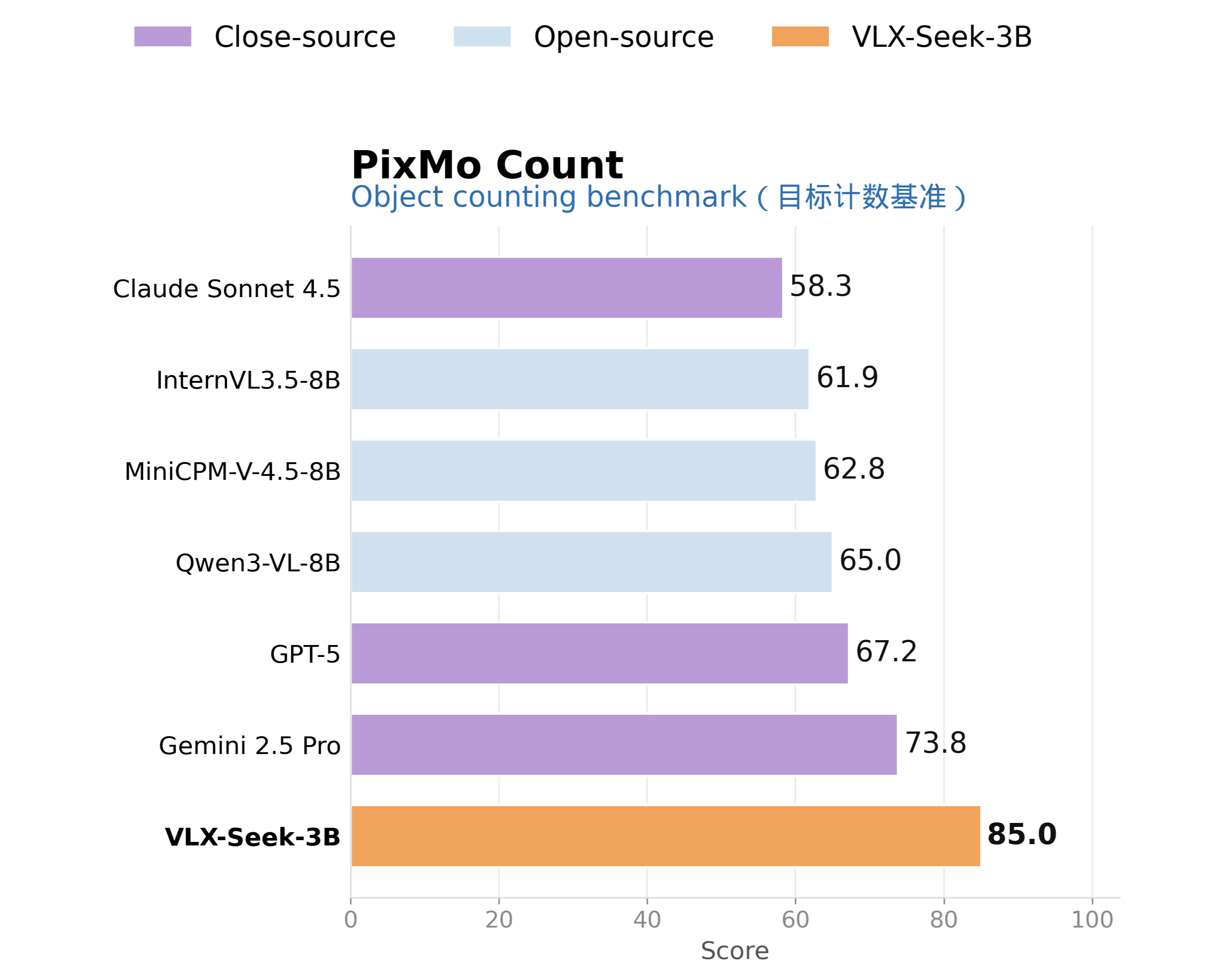
在目标计数上,VLX-Seek-3B 在 PixMo-Count 上达到 85.0,高于 Gemini 2.5 Pro 的 73.8。计数任务看似简单,但对 VLM 来说一直不容易,因为模型如果只依赖全局语义,很容易估多或估少。VLX-Seek 的优势在于,它可以先检测并引用目标实例,再进行聚合计数。这种“先检测、再计数”的方式,比直接让模型凭画面印象估数量更可靠。
具体分数对比
一句话总结,VLX-Seek 的技术价值在于:它让 VLM 更像一个真正能“看细节”的视觉系统,而不只是一个能描述画面大意的语言接口。
八、VLX-Seek 和传统方案有什么不同?
相比普通 VLM,VLX-Seek 的不同在于,它不满足于描述画面,而是显式建模图像中的候选区域。普通 VLM 可以回答“画面里有几个人”,但在复杂定位、目标计数和开放词汇检测中容易不稳定。VLX-Seek 通过区域 token 把目标实例引入模型,让模型具备更强的细节定位能力。
相比专用检测器,VLX-Seek 的不同在于,它不只是输出固定类别的边界框。传统检测器在封闭类别上很稳定,但对自然语言描述、开放词汇类别、复杂关系和多轮指代的理解有限。VLX-Seek 借助 VLM 的语言理解和世界知识,让检测与语义推理结合起来。
相比坐标生成式 VLM,VLX-Seek 的不同在于,它不让语言模型直接承担精确数值生成的压力。坐标生成很容易受到格式错误、长序列累积误差和多目标漏检影响,而区域引用更接近 LLM 擅长的指代和选择任务。同时,VLX-Seek 的推理效率也更高:生成式 VLM 往往需要为每个目标输出完整坐标序列,而 VLX-Seek 只需要输出对应的区域索引。目标越多,区域引用在输出长度和解码开销上的优势越明显。
相比外接检测头的方案,VLX-Seek 的不同在于,它不是简单把检测结果附加到 VLM 外部,而是把区域变成模型内部可以读取和引用的视觉语言实体。这样,区域不只是最终输出结果,而是可以真正参与语言推理过程。
这种设计让 VLX-Seek 兼具两类能力:一方面,它继承了检测器对空间区域的召回能力;另一方面,它保留了 VLM 对自然语言、开放类别和复杂语义关系的理解能力。
九、技术价值:以细粒度定位支撑具身行动
VLX-Seek 的核心价值,是让 VLM 不再只会“描述画面”,而是能用更小的模型规模看清目标、锚定目标。它让小参数 VLM 也能在目标检测、开放词汇定位、复杂指代表达、区域 OCR 和目标计数等任务中达到接近甚至超过更大模型的效果。这一点对具身设备非常关键,因为机器人、无人机、摄像头和边缘终端真正需要的,不只是一个离线评测分数更高的大模型,而是一个能在有限算力、显存和功耗下持续运行的感知模块。
更小的模型、更快的推理,也意味着更低的部署成本。对于端侧具身设备来说,模型越轻,所需算力和显存越低,运行功耗越可控,对高规格 GPU 或云端推理的依赖也越少。这不仅降低了硬件成本和推理成本,也减少了端云传输带来的延迟、带宽占用和隐私风险。换句话说,VLX-Seek 的价值不只是“看得更准”,还在于它让细粒度视觉感知更接近真实设备可以长期运行的形态。
更重要的是,具身系统要行动,必须先有稳定的空间锚点。它需要知道目标在哪里、是哪一个、是否还在,以及和周围环境是什么关系。VLX-Seek 补上的正是这层区域级感知能力:它可以为跟随、避障、巡检、抓取、导航和多轮交互提供清晰的目标位置与视觉依据。对于端侧具身智能来说,这不是锦上添花,而是从“看懂画面”走向“可执行行动”的基础能力。
更多技术细节和开源项目,请访问:om-ai-lab/VLX-Seek。